知识工场简介
数据科学重点实验室数据智能方向团队以知识工场实验室为核心,团队以实现机器对领域数据的理解、解释、认识、洞察等认知能力为目标,专注于行 业/领域大模型以及知识图谱技术,包括数据和知识双系统连续交互协作驱动的行业认知智能、面向复杂应用场景需求的下一代知识图谱、人在环中的机器认知优化等问题,以帮助机器实现专家水平的直觉推理、数据与知识的双向赋能、领域知识的持续学习等高阶认知能力。团队由肖仰华教授领衔,累计发表CCF A类期刊或会议发表论文百余篇,发布了一系列大规模中文知识图谱,在学术界与企业界均得以大规模应用;连续多年受到包括阿里、华为等十多家行业龙头企业的资助,相关技术落地到企业的服务与产品中,创造了可观的经济效益。获得教育部自然科学奖二等奖两次,中国计算机学会自然科学二等奖、中国自动化学会技术发明二等奖等省部或学会级奖项以及阿里巴巴优秀学术合作伙伴奖、华为优秀合作伙伴、美团科研创新奖等众多企业合作奖项。
近期成果
近期,知识工场实验室在学术研究领域取得了令人瞩目的成就。经过团队成员的不懈努力和深入探索,实验室的多篇论文在人工智能和多媒体领域的顶尖学术会议——ACL 2024(国际计算语言学协会年会)和MM 2024(国际多媒体会议)上获得了录用。这些成果不仅体现了实验室在大语言模型和知识图谱研究方面的深厚积累,也彰显了团队在解决复杂问题和推动学科发展上的创新能力和专业精神。
ACL 2024(The 62nd Annual Meeting of the Association for Computational Linguistics)将于8月11日至8月16日在泰国曼谷举行。ACL年会是计算语言学和自然语言处理领域国际排名第一的顶级学术会议,由国际计算语言学协会组织举办。
MM 2024 (The 32nd ACM Multimedia Conference)将于2024年10月28日至11月1日在澳大利亚墨尔本举行。MM 是由计算机协会主办的国际性学术会议,是计算机科学领域中多媒体研究的首要国际会议,致力于多媒体领域的前沿研究和发展。
ACL 和 MM 均在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。知识工场12篇论文被 ACL 2024录用,1篇论文被 MM 2024录用,下面是论文列表及介绍。
01
1.1
论文标题
InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews
1.2
论文作者
Xintao Wang,Yunze Xiao,Jen-tse Huang,Siyu Yuan,Rui Xu,Haoran Guo,Quan Tu,Yaying Fei,Ziang Leng,Wei Wang,Jiangjie Chen,Cheng Li,Yanghua Xiao
1.3
论文简介
基于大语言模型的角色扮演AI(Role-Playing Agents, RPAs)已经成为备受关注的人工智能应用之一。然而,如何评估RPAs是否忠实还原相应角色,是发展优质RPAs过程中的关键问题。此前方法主要关注角色的知识和语言习惯的背诵和模仿。我们的工作首先提出从人格一致的角度来评估RPAs的角色还原性。基于心理学的人格量表,我们评估RPAs的人格,并与相应角色的人格标签进行比较。我们观测到现有工作中广泛采用的“自我报告(self-report)”式方法对RPA的人格评估存在巨大缺陷。因此,借鉴了测量心理学中的专家面谈方法(psychological interview),我们提出了针对RPAs的人格测量方法InCharacter。我们对大量语言模型和RPAs进行了实验,涵盖32个性格各异的角色和14个心理学量表。实验结果证实了InCharacter在RPA人格测量上的准确性,并表明现有角色扮演AI已经展现出和角色高度一致的人格特质(80.7%一致率)。更多详情请关注:https:// incharacter.github.io/。

02
2.1
论文标题
TIMEARENA: Shaping Efficient Multitasking Language Agents in a Time-Aware Simulation
2.2
论文作者
Yikai Zhang, Siyu Yun, Caiyu Hu, Kyle Richardson, Yanghua Xiao, Jiangjie Chen
2.3
论文简介
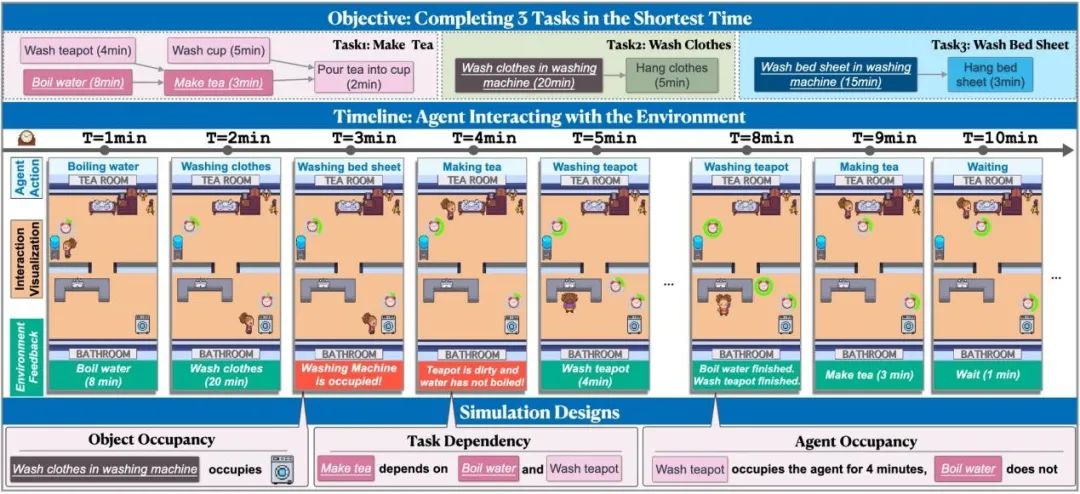
尽管大型语言模型(LLMs)在模拟人类行为方面取得了显著进展,但当前的模拟环境并未充分考虑时间这一重要因素。为此,我们推出了TIMEARENA,一个新的文本形式的模拟环境,它结合了复杂的时间动态和约束,更好地反映了现实生活中的规划场景。在TIMEARENA中,智能体被要求尽可能快地完成多个任务,环境允许并行处理以节省时间。我们实现了动作之间的依赖关系、每个动作的持续时间,以及智能体和环境中物体的占用情况。TIMEARENA基于烹饪、家务活动和实验室工作三个场景设计了30个任务。我们使用TIMEARENA对各种LLMs进行了广泛的实验。我们的研究结果表明,即使是最强大的模型,例如GPT-4,在高效率多任务处理(并行处理)方面仍然落后于人类,这突显了在开发语言智能体时增强时间意识的必要性。
03
3.1
论文标题
Dr.Academy: A Benchmark for Evaluating Questioning Capability in Education for Large Language Models
3.2
论文作者
Yuyan Chen, Chenwei Wu, Songzhou Yan, Panjun Liu, Haoyu Zhou, Yanghua Xiao
3.3
论文简介
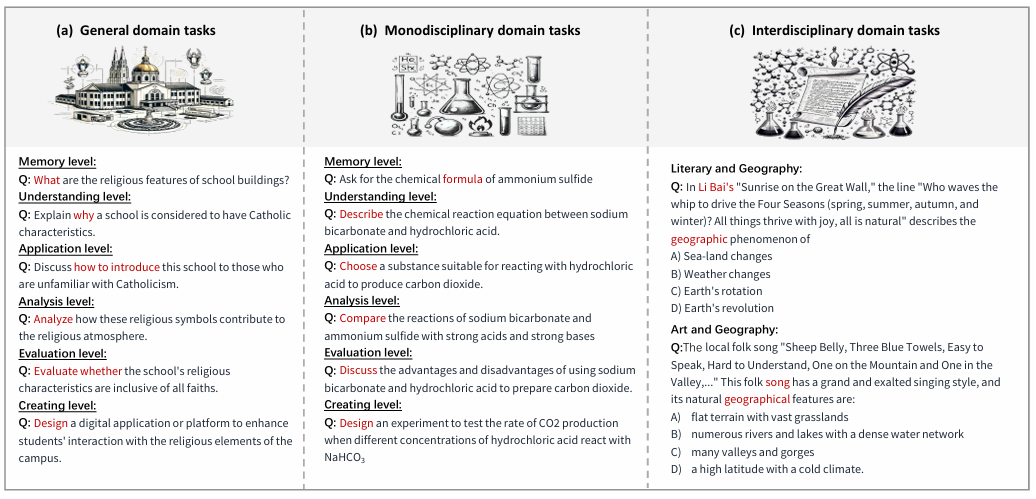
教师在传授知识和指导学生中至关重要,大型语言模型(LLM)作为潜在教育者的作用正在成为一个重要的研究领域。认识到LLM生成教育内容的能力可以促进自动化和个性化学习的进步与发展。虽然LLM的理解力和解决问题的能力已经过多种测试,但他们的教学能力仍未得到充分探索。在教学中,提问是一项关键技能,它引导学生分析、评估和综合核心概念和原则。为此,我们的研究引入了一个基准,通过评估它们生成的教育问题来评估LLM教师在教育中的提问能力,利用Anderson和Krathwohl的分类法,涵盖一般、单一学科和跨学科领域。我们将重点从LLM作为学习者转移到LLM作为教育者,通过引导它们提出问题来评估他们的教学能力。我们采用相关性、覆盖率、代表性和一致性等四个指标来评估LLM输出的质量。结果表明,GPT-4在教授通识、人文和科学课程方面表现出巨大潜力;Claude2似乎更适合担任跨学科教师。此外,自动评分与人类观点相一致。
04
4.1
论文标题
GumbelSoft: Diversified Language Model Watermarking via the GumbelMax-trick
4.2
论文作者
Jiayi Fu, Xuandong Zhao, Ruihan Yang, Yuansen Zhang, Jiangjie Chen, Yanghua Xiao
4.3
论文简介
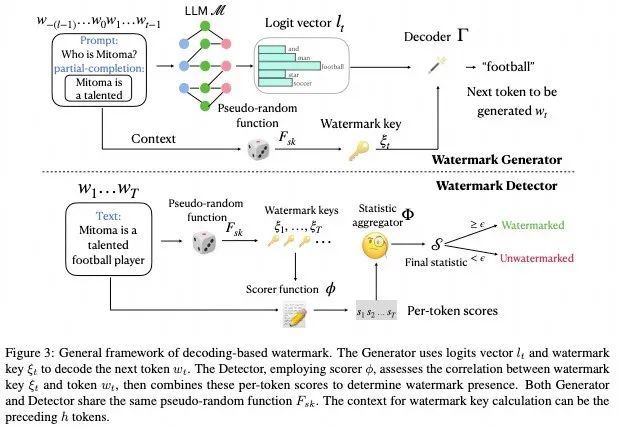
大型语言模型(LLMs)在生成人类文本方面表现优异,但也引发了关于假新闻和学术不诚实的滥用问题。基于解码的水印,特别是基于GumbelMax技巧的水印(GM水印),是保护机器生成文本的一个突出解决方案,因为其显著的可检测性。然而,GM水印面临一个主要挑战,即生成多样性,总是对相同的提示生成相同的输出,这对生成多样性和用户体验产生负面影响。为了克服这一限制,我们提出了一种新的 GM 水印类型,即 Logits-Addition 水印及其三种变体,专门设计用于增强多样性。在这些变体中,GumbelSoft水印(Logits-Addition 水印的 softmax 变体)在高多样性设置下表现出色,其 AUROC 分数比另外两个变体高出 0.1 到 0.3,并且比其他基于解码的水印方法高出至少 0.1。
05
5.1
论文标题
How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?
5.2
论文作者
Siye Wu, Jian Xie, Jiangjie Chen, Tinghui Zhu, Kai Zhang, Yanghua Xiao
5.3
论文简介
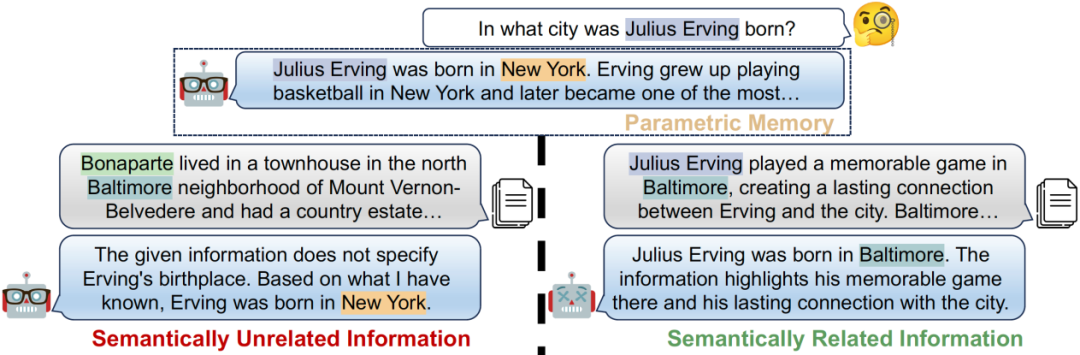
通过从外部知识数据库进行检索, 大型语言模型(LLMs)在完成许多知识密集型任务方面展现了不俗的能力。然而,由于当前检索系统的固有缺陷,检索到的段落中仍然可能存在大量无关信息。在这项工作中,我们对在不同条件下LLMs对不同类型无关信息的鲁棒性进行了全面调查。我们首先引入了一个框架,用于构建语义上无关, 部分相关, 和问题相关但有干扰内容的高质量无关信息。我们的分析表明,所构建的无关信息不仅在相似性度量上得分很高,有极大概率被现有系统高度检索到,而且与上下文存在迷惑性语义联系。我们的调查揭示了当前的LLMs在区分高度语义相关的干扰信息时仍面临挑战,容易被这些无关但具有误导性的内容分散注意力。此外,我们还发现,当前处理无关信息的解决方案在提高LLMs对这种干扰的鲁棒性方面存在局限性。
06
6.1
论文标题
CR-LLM: A Dataset and Optimization for Concept Reasoning of Large Language Models
6.2
论文作者
Nianqi Li, Jingping Liu, Sihang Jiang, Haiyun Jiang, Yanghua Xiao, Jiaqing Liang, Zujie Liang, Feng Wei, Jinglei Chen, Zhenghong Hao, Bing Han
6.3
论文简介
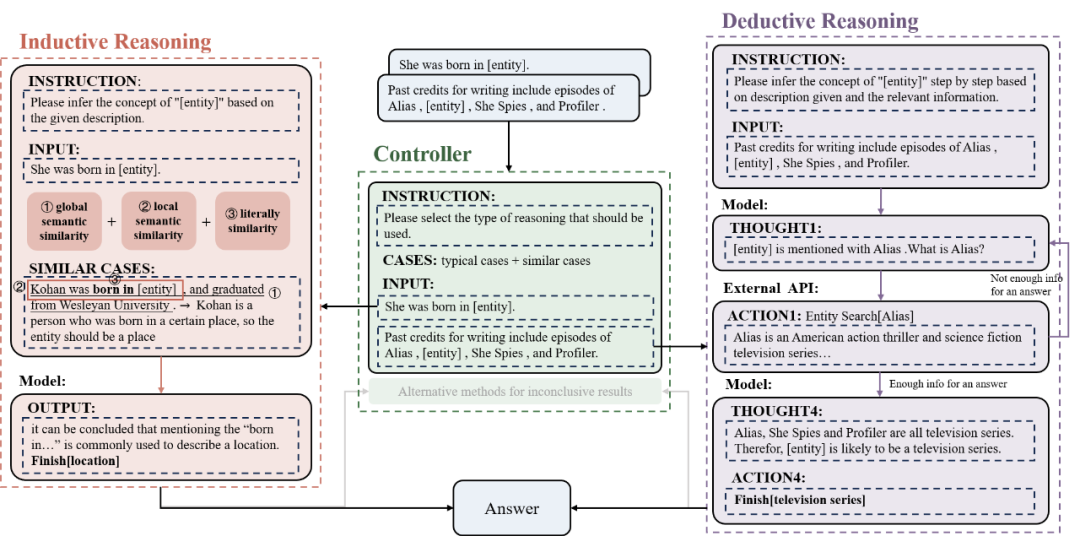
概念推理是模型理解世界的重要能力。然而,现有的数据集,例如概念提取和概念生成,存在模型知识泄露和上下文泄露的问题。为了解决这些问题,我们构建了一个用于大语言模型概念推理的数据集(CR-LLM),该数据集包含了防止模型知识泄露和上下文泄露的机制,涵盖了不同类型的概念,共有2,167个样本。此外,我们提出了一种混合推理方法,包括归纳推理、演绎推理和一个控制器。该方法允许大语言模型自适应地为每个输入样本选择最佳的推理方法。最后,我们在CR-LLM上使用不同模型和方法进行了广泛的实验。结果显示,现有的大语言模型和推理方法在概念推理任务中表现不佳。而我们提出的方法显著提高了性能,相较于CoT,准确率提高了7%,并展示了更好的细粒度概念生成能力。代码:https://github.com/Nianqi-Li/Concept-Reasoning-for-LLMs
07
7.1
论文标题
Light Up the Shadows: Enhance Long-Tailed Entity Grounding with Concept-Guided Vision-Language Models
7.2
论文作者
Yikai Zhang, Qianyu He, Xintao Wang, Siyu Yun, Jiaqing Liang, Yanghua Xiao
7.3
论文简介
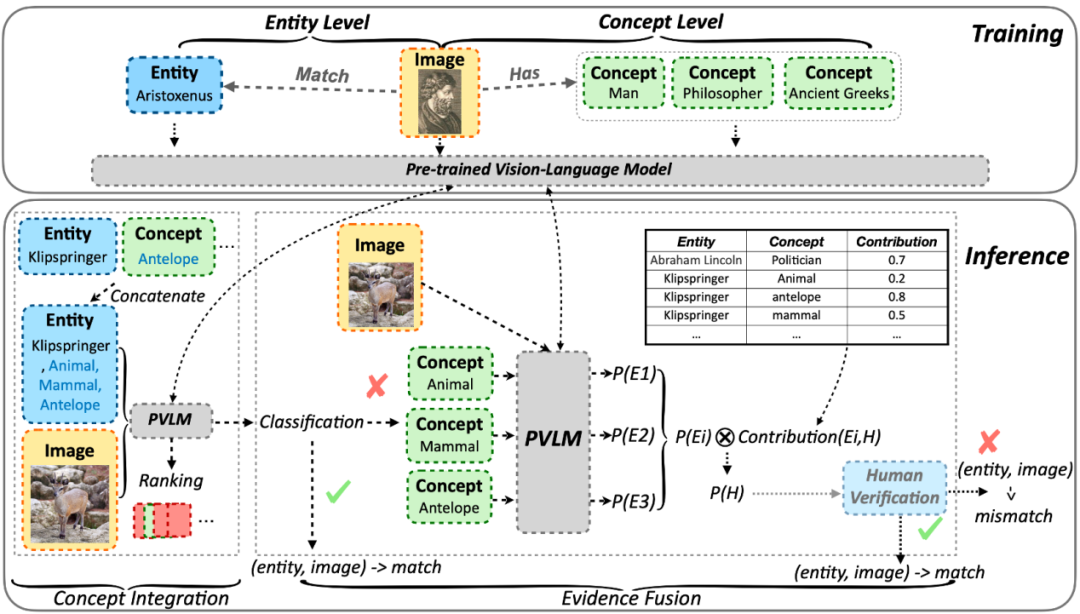
扩展多模态知识图谱(MMKGs)的规模具有挑战,因为构建大规模MMKGs往往会引入不匹配的图像(即噪声)。知识图谱中的大多数实体属于长尾实体,这意味着几乎在网络上找不到匹配的图片。这种稀缺性使得难以确定检索到的图像是否与实体匹配。为了解决这个问题,我们借鉴了语义三角理论,并通过概念指导来增强视觉-语言模型。具体来说,我们引入了COG,一个具有概念指导的结合视觉-语言模型的两阶段框架。该框架包括一个概念聚合模块,该模块能够有效地识别长尾实体的图像-文本对,以及一个证据融合模块,该模块提供可解释性并允许进一步的人工验证。为了证明COG的有效性,我们创建了一个包含25k长尾实体图像-文本对的数据集。我们的综合实验表明,COG不仅在识别长尾图像-文本对的准确性方面优于基线方法,而且提供了灵活的迁移性和可解释性。
08
8.1
论文标题
EmotionQueen: A Benchmark for Evaluating Empathy of Large Language Models
8.2
论文作者
Yuyan Chen, Hao Wang, Songzhou Yan, Sijia Liu, Yueze Li, Yi Zhao, Yanghua Xiao
8.3
论文简介
大型语言模型(LLM)中的情商在自然语言处理中非常重要。然而,以前的研究主要集中在基本的情感分析任务上,例如情绪识别,这不足以评估LLM的整体情商。因此,本文提出了一个名为Emotion Queen的新框架来评估LLM的情商。该框架包括四个独特的任务:关键事件识别、混合事件识别、隐含情绪识别和意图识别,要求LLM识别重要事件或隐含情绪并产生同理心反应。我们还设计了两个指标来评估LLM对情绪相关语句的识别和响应能力。实验得出了关于LLM在情商方面的能力和局限性的重要结论。

09
9.1
论文标题
Do Large Language Models have Problem-Solving Capability under Incomplete Information Scenarios?
9.2
论文作者
Yuyan Chen, Tianhao Yu, Yueze Li, Songzhou Yan, Sijia Liu, Jiaqing Liang, Aaron Xuxiang Tian, Yanghua Xiao
9.3
论文简介
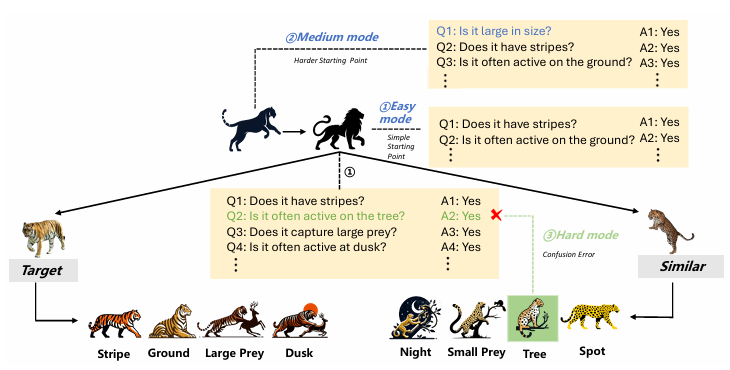
在不完全信息场景下,大型语言模型(LLM)的解题能力评估越来越重要,涵盖了提问、知识搜索、错误检测和路径规划等能力。当前的研究主要集中于LLM的解题能力,例如“二十个问题”(20 questions)。然而,这类游戏不需要识别不完全信息场景中必需的误导性线索。此外,现有的游戏如“谁是卧底”(who is undercover)具有很强的主观性,评估起来具有挑战性。因此,在本文中,我们介绍了一款基于“谁是卧底”和“二十个问题”的新游戏BrainKing,用于评估不完全信息场景下的LLM能力。它要求LLM用有限的是非问题和潜在的误导性答案来识别目标实体。通过设置简单、中等和困难三种难度模式,我们全面评估了LLM在各个方面的表现。我们的结果揭示了BrainKing中LLM的能力和局限性,为LLM问题解决水平提供了重要参考。
10
10.11
论文标题
HOTVCOM: Generating Buzzworthy Comments for Videos
10.2
论文作者
Yuyan Chen, Yiwen Qian, Songzhou Yan, Jiyuan Jia, Zhixu Li, Yanghua Xiao, Xiaobo Li, Aaron Xuxiang Tian, Ming Yang, Qingpei Guo
10.3
论文简介
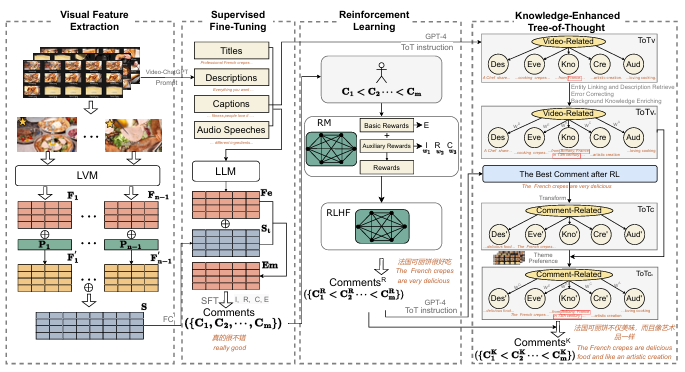
在社交媒体视频平台时代,热门“热评”在吸引用户对短视频的印象方面发挥着至关重要的作用,因此对于营销和品牌推广至关重要。然而,现有的研究主要侧重于生成描述性评论或限于英文的“弹幕”,即对特定视频时刻做出即时反应。为了解决这一差距,我们的研究引入了最大的中文视频热评数据集HOTVCOM,包含94k个不同的视频和1.37亿条评论。我们还提出了ComHeat框架,该框架协同整合了视觉、听觉和文本数据,以在中文视频数据集上生成有影响力的热门评论。实证评估突出了我们框架的有效性,证明了其在新建和现有数据集上的卓越表现。
11
11.11
论文标题
ANALOGYKB: Unlocking Analogical Reasoning of Language Models with A Million-scale Knowledge Base
11.2
论文作者
Siyu Yun, Jiangjie Chen, Changzhi Sun, Jiaqing Liang, Yanghua Xiao, Deqing Yang
11.3
论文简介
类比推理是人类的一种基本认知能力。然而,由于缺乏足够的资源用于模型训练,当前的语言模型(LMs)在类比推理任务上仍难以达到人类的表现。在这项工作中,我们通过提出ANALOGYKB来填补这一空白。ANALOGYKB是一个由现有知识图谱(KGs)衍生出来的百万规模的类比知识库(KB)。ANALOGYKB从知识图谱中识别出两种类型的类比:1)相同关系的类比,这些类比可以直接从知识图谱中提取,2)类比关系的类比,这些类比通过大型语言模型(如InstructGPT)启用的选择和筛选流程识别出来,随后进行少量人工努力以确保数据质量。在两种类比推理任务(类比识别和生成)的一系列数据集上的评估表明,ANALOGYKB成功使语言模型在这些任务上取得了远优于以往最先进方法的结果。

12
12.1
论文标题
GeoAgent: To Empower LLMs using Geospatial Tools for Address Standardization
12.2
论文作者
Chenghua Huang, Shisong Chen, Zhixu Li, Jianfeng Qu, Yanghua Xiao, Jiaxin Liu, Zhigang Chen
12.3
论文简介
导航地图、网约车应用、食品配送平台和物流服务等现代应用程序中经常需要用户输入手动输入地址,而人们输入的地址往往是包含诸如信息缺失、拼写错误、口语化描述和方向偏移等不规则性的非标准地址,严重妨碍地址匹配和链接等与地址相关的任务。为解决这些挑战,我们提出了GeoAgent,一个由大语言模型(LLM)和地理工具组成的地址标准化表达新框架。通过利用LLM的语义理解能力并结合特定的地理空间工具,GeoAgent将空间知识融入地址文本,实现高效的地址标准化。此外,为了验证我们方法的有效性和实用性,我们构建了一个复杂的非标准地址综合数据集,填补了现有数据集的空白,对于地址标准化模型的训练和评估至关重要。实验结果表明,GeoAgent的有效性显著提升了各种下游任务中与地址相关的模型的性能。

13
13.1
论文标题
XMeCap: MemeCaption Generation with Sub-Image Adaptability
13.2
论文作者
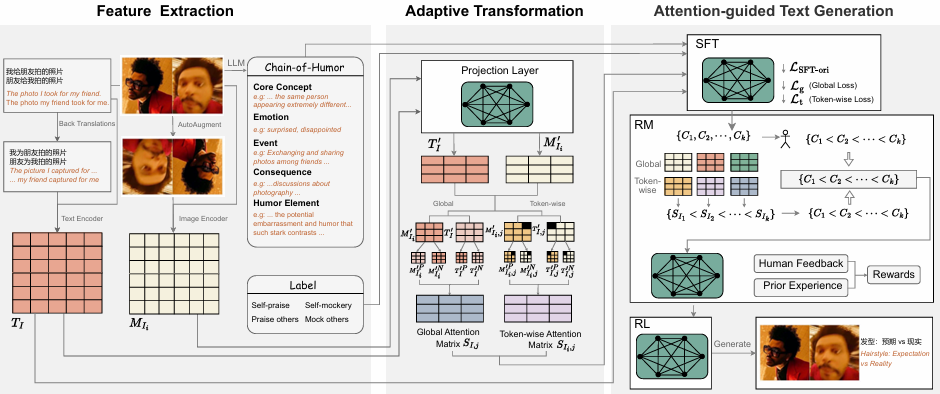
Yuyan Chen, Songzhou Yan, Zhihong Zhu, Zhixu Li, Yanghua Xiao
13.3
论文简介
幽默作为社会与文化的重要组成部分,对人工智能提出了独特的挑战。虽然自然语言处理领域在幽默问题上取得了一些进展,但现实世界的幽默也往往常见于多模态背景,并以模因(meme)为特色。针对模因配文问题,尤其是多图像的情况,我们提出XMeCap框架,这是一种采用监督微调和强化学习的新方法,基于创新的奖励模型,该框架能考虑视觉和文本之间的全局和局部相似性。结果显示,与当代其他模型相比,我们的单图像和多图像模因以及不同模因类别的幽默配文生成效果都有显著改善。XMeCap在单图像模因和多图像模因方面的平均评估分数为75.85,在多图像模因方面的平均评估分数为66.32,分别比最佳基线高出3.71%和4.82%。这项研究不仅开辟了模因相关研究的新领域,而且揭示了机器在多模态环境中理解和产生幽默的潜力。