FIAI Lab 简介
团队以工业智能为核心,针对实际工业场景中目标识别、异常检测以及产品质量控制中存在的问题,研究相应工业AI解决方案,涉及的AI技术主要包含主动学习、迁移学习/知识蒸馏、对比学习、(2D/3D图像)多模态融合、扩散模型的优化和加速、深度图像重构、视觉图神经网络、多模态多目标视频跟踪、深度解混网络、多模态(大)模型等,实现在高速高清工业场景下产品的异常或瑕疵实时检测,并为学术界提供真实多模态(异常)检测和变化检测数据。当前,已成功将以上研究和创新算法应用于实际工业场景,并研制多款智能瑕疵检测以及智能识别产品,部分工作获得2024年“发明创业奖·成果奖”二等奖。
团队以池明旻副教授(mmchi@fudan. edu.cn)领衔,已发表60余篇高质量的会议和期刊论文,包括AAAI、ACM MM、CVPR、ICCV、ICML、IJCAI、Proceedings of the IEEE等顶级人工智能和计算机视觉国际会议和刊物论文,授权发明专利十余项。承担多项国家自然基金项目、国家重点研发项目以及人工智能和大数据主题相关的横向课题(来自于如腾讯优图、荣旗科技、阿里巴巴、蚂蚁金服、中石化等)。依托国家大科学装置FAST——500米口径射电望远镜,国家天文台、腾讯优图共同发布“探星计划”,已成功找到近50颗新脉冲星,该项目获得2022年世界人工智能大会的“SAIL”奖。
近期成果
01
工业多模态异常检测数据发布
1.1
论文标题
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection, CVPR 2024.
1.2
论文作者
Chengjie Wang, Wenbing Zhu, Bin-Bin Gao, Zhenye Gan, Jiangning Zhang, Zhihao Gu, Shuguang Qian, Mingang Chen, Lizhuang Ma.
1.3
论文简介
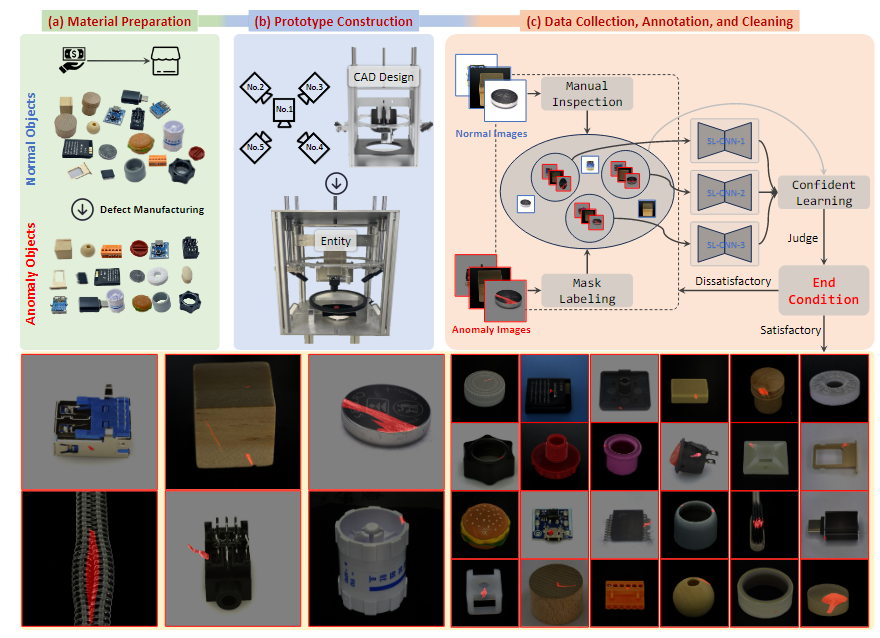
工业异常检测(IAD)这个领域目前受到广泛的关注,并且正在经历快速的发展。然而,IAD方法的发展因数据集的限制而遇到了一些困难。一方面,大多数最先进的方法在主流数据集(如MVTec)上已经达到了饱和(AUROC超过99%),方法之间的差异难以区分,这导致公共数据集与实际应用场景之间存在显著差距。另一方面,各种新的实际异常检测设置的研究受到数据集规模的限制,评估结果存在过拟合的风险。因此,本论文提出了一个大规模的、真实世界的、多视角的工业异常检测数据集,命名为Real-IAD,该数据集包含150,000张高分辨率图像,涵盖30种不同的对象,规模比现有数据集大一个数量级。它具有更广泛的缺陷区域和比例,使其比以前的数据集更具挑战性。为了使数据集更接近实际应用场景,我们采用了多视角拍摄方法,并提出了样本级评估指标。此外,除了通用的无监督异常检测设置外,我们还基于工业生产中通常超过60%的良品率观察,提出了一种完全无监督工业异常检测(FUIAD)新设置,这具有更实际的应用价值。最后,我们展示了主流的IAD方法在Real-IAD数据集上的结果,提供了一个高度具有挑战性的基准,以促进IAD领域的发展。
02
工业图像异常检测算法
2.1
论文标题
Learning Unified Reference Representationfor Unsupervised Multi-class Anomaly Detection, ECCV 2024.
2.2
论文作者
Liren He, Zhengkai Jiang, Jinlong Peng, Wenbing Zhu, Liang Liu, Qiangang Du, Xiaobin Hu, Mingmin Chi,Yabiao Wang, Chengjie Wang.
2.3
论文简介
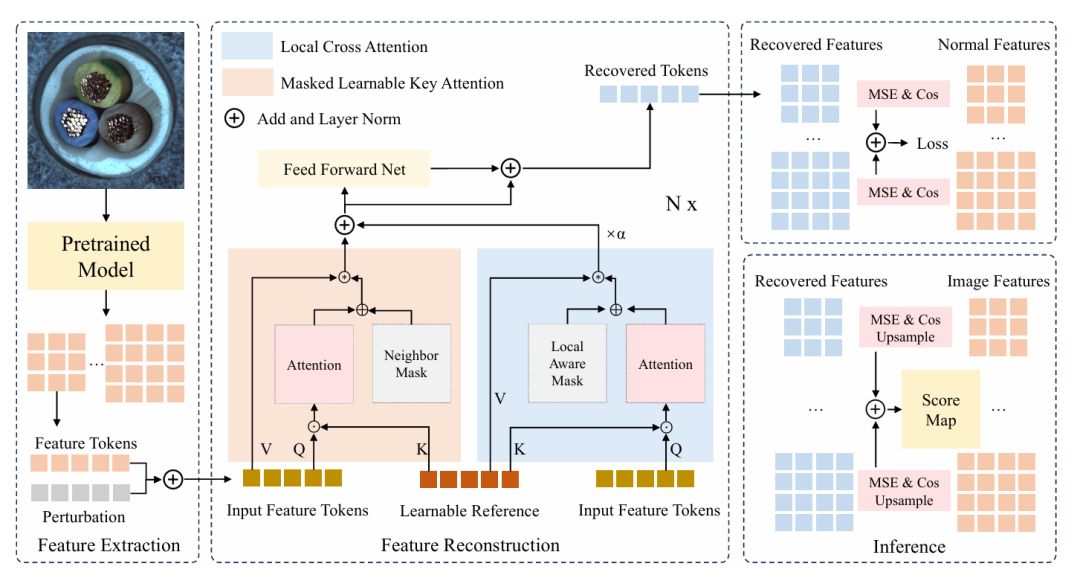
在多类异常检测领域,基于单类异常检测的重构方法面临着众所周知的“学习捷径”挑战,即模型无法按应有的方式学习正常样本的模式,而是选择诸如恒等映射或人工噪声消除之类的捷径。因此,该模型无法将真正的异常重建为正常实例,从而导致异常检测失败。为了解决这个问题,我们提出了一种新的统一的基于特征重构的异常检测框架,称为 RLR(从可学习参考表示重构特征)。与以前的方法不同,RLR 利用可学习的参考表示来强制模型明确学习正常的特征模式,从而防止模型屈服于“学习捷径”问题。此外,RLR 将局部性约束纳入可学习参考中,以促进更有效地捕获正常模式,并利用掩码的可学习关键注意机制来增强鲁棒性。在 15 类MVTecAD 数据集和12 类 VisA 数据集上对 RLR 的评估表明,与统一设置下最先进的方法相比,RLR 具有更优异的性能。
03
工业图像变化检测算法
3.1
论文标题
Align, Perturb and Decouple: Toward Better Leverage of Difference Information for RSI Change Detection,IJCAI 2023.
3.2
论文作者
Supeng Wang, Yuxi Li, Ming Xie, Mingmin Chi, Yabiao Wang, Chengjie Wang, and Wenbing Zhu.
3.3
论文简介
变化检测是遥感影像 (RSI) 分析中广泛采用的一种技术,用于发现长期地貌演变。为了突出语义变化的区域,以前的工作主要关注学习单个图像的代表性特征描述,而差异信息要么用简单的差异操作建模,要么通过特征交互隐式嵌入。然而,这种差异建模可能会很嘈杂,因为它受到非语义变化的影响,并且缺乏来自图像内容或上下文的明确指导。在本文中,我们重新审视特征差异对于 RSI 中变化检测的重要性,并提出了一系列操作来充分利用差异信息:对齐、扰动和解耦 (APD)。首先,对齐利用上下文相似性来补偿特征空间中的非语义差异。接下来,采用经过语义扰动训练的差异模块来学习更广义的变化估计器,从而反向引导特征提取和预测。最后,设计了一个解耦的双解码器结构,以内容感知和内容无关的方式预测语义变化。在LEVIR-CD、WHU-CD 和 DSIFN-CD 的基准上进行了广泛的实验,证明了我们提出的操作在类似的比较条件下带来了显著的改进并取得了有竞争力的结果。

04
智能纺织品纤维检测算法
(深度解混网络)
4.1
论文标题
Solving Spectrum Unmixing as a Multi-task Bayesian Inverse Problem with Latent Factors for Endmember Variability, AAAI 2024.
4.2
论文作者
Dong Wu, Mingmin Chi, Xuan Zang, and Po Peng.
4.3
论文简介
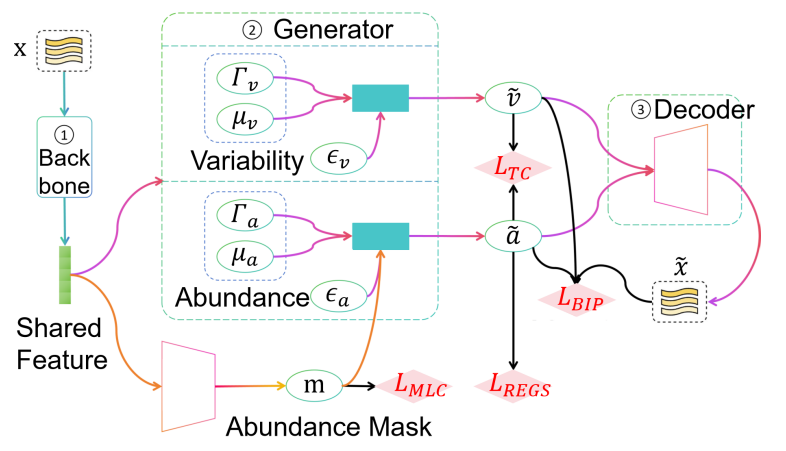
随着光谱仪定制化程度的不断提高,光谱非混合技术已在遥感、纺织和环境保护等领域得到广泛应用。然而,末端成员的可变性是解混技术的一个常见问题,光照、大气、时间条件的变化或材料固有的光谱特性都会导致测量光谱的变化。最近的研究采用了深度神经网络来解决内元变异性问题。然而,这些方法依赖于通用网络来隐式地解决这一问题,而通用网络在解决内含体变异性的问题上存在困难,而且缺乏有效的收敛约束。本文提出了一种简化的多任务学习模型来纠正这一问题,将丰度回归和多标签分类与非混合作为贝叶斯逆问题(BIPU)结合起来。为了解决不确定性的问题,在贝叶斯逆求解器中通过拉普拉斯近似对非混合的不确定性进行量化和最小化。此外,为了在末端成员变化的影响下提高收敛性,本文引入了两类约束条件。第一种方法是将变体的背景因素从每个内元的初始因素中分离出来,第二种方法是在收敛过程中通过多标签分类来识别和消除不存在的内元的影响。该模型的有效性不仅在自收集的近红外光谱纺织品数据集(FENIR)上得到了验证,而且在三个常用的遥感高光谱图像数据集上也得到了验证。
05
智能纺织品纤维检测算法
(深度多模态融合网络)
5.1
论文标题
Image-Signal Correlation Network for Textile Fiber Identification, ACM MM 2022.
5.2
论文作者
Bo Peng, Liren He, Yining Qiu, Wu Dong, Mingmin Chi.
5.3
论文简介
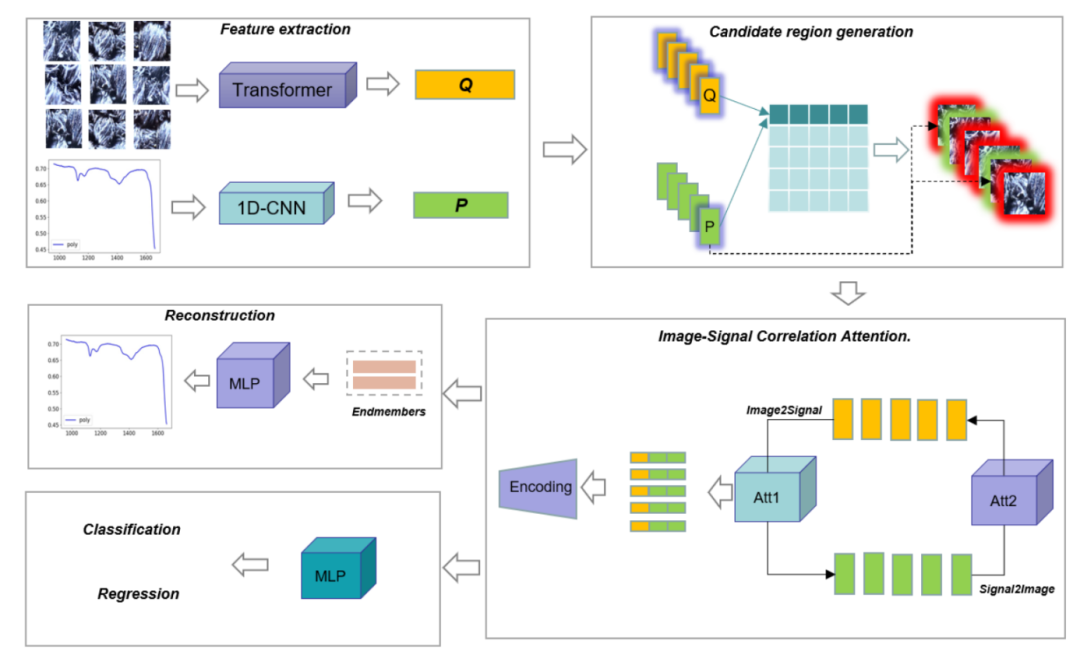
识别纤维成分是纺织业的一个重要方面。近几十年来,近红外光谱技术在自动检测纤维成分方面显示出了巨大的潜力。然而,对于棉花和亚麻等植物纤维来说,其化学成分是相同的,因此吸收率也是相同的。然而,对于棉花和亚麻等植物纤维而言,其化学成分相同,因此吸收光谱非常相似,这就导致了“不同材料具有相同光谱,而相同材料具有不同光谱 ”的问题,而且使用单一模式的近红外信号很难捕捉到有效的特征来区分这些纤维。为了解决这个问题,纺织专家们在显微镜下测量纤维的横截面或纵向特征,以破坏性的方式确定纤维含量。本文构建了首个近红外信号显微图像纺织纤维成分数据集(NIRITFC)。基于NIRITFC数据集,我们提出了一种图像信号相关网络(ISiC-Net),并分别设计了图像信号相关感知模块和图像信号相关注意模块,以有效整合视觉特征(尤其是纤维的局部纹理细节)和近红外信号更精细的吸收光谱信息,从而捕捉双模数据的深层抽象特征。实现纺织纤维的无损识别。为了更好地了解纤维成分的光谱特征,通过嵌入编码生成了相应纤维的端元向量,并设计了重构损耗,引导模型通过非线性映射重构相应纤维成分的近红外信号。与单模态和双模态方法相比,该方法的定量和定性结果均有明显改善,表明将显微图像和近红外信号结合起来用于纺织纤维成分识别具有巨大潜力。
06
基于联邦学习的工业数据
安全学习算法
6.1
论文标题
Non-IID Federated Learning via Random Exchange of Local Feature Maps for Textile IIoT Secure Computing, SCIENCE CHINA Information Sciences 2022 (中国科学·信息科学).
6.2
论文作者
Bo Peng, Mingmin Chi, Chao Liu.
6.3
论文简介
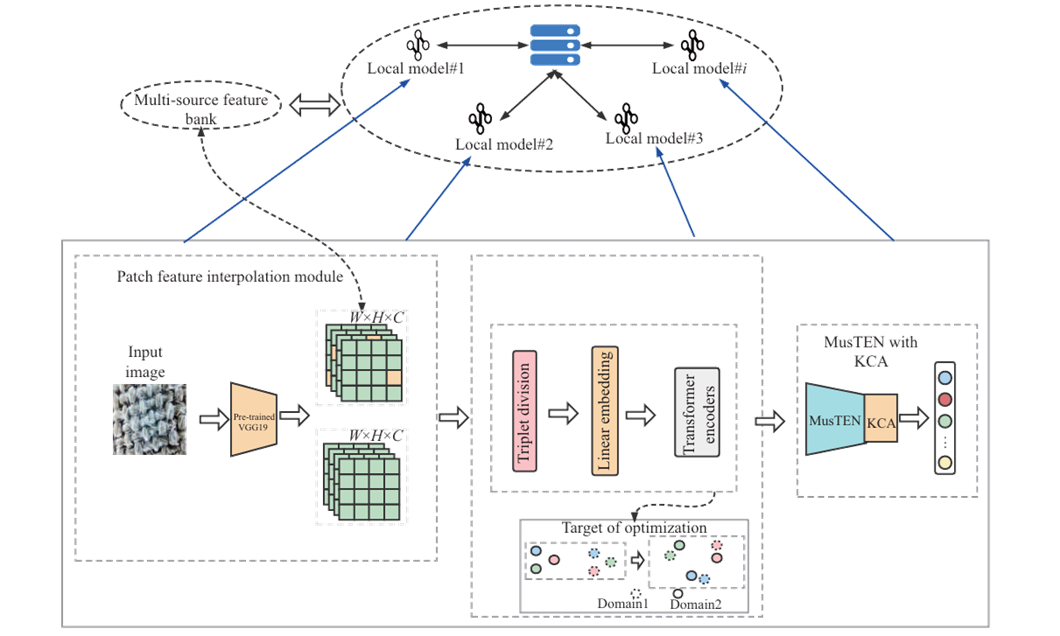
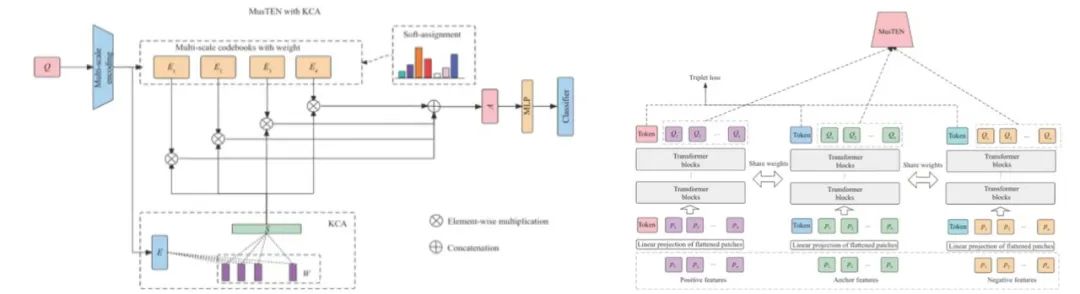
随着人工智能(AI)和工业物联网(IIoT)技术的快速发展,数据隐私保护和安全计算问题日益严峻。近年来,联邦学习(FL)被提出来应对基于跨域客户端数据协同学习共享模型并保护安全性的挑战。然而,由于业务、工作环境和数据获取的差异,现实环境中的数据通常不是独立同分布的(Non-IID),因此经典的联邦方法性能会显著下降。本文提出了一种新的联邦框架,通过基于高清织物图像的跨域纹理表示实现安全纺织纤维识别(FedTFI)。除了共享 FedTFI 的梯度之外,跨域客户端之间的局部特征图块被随机交换以构建更丰富的图像纹理特征分布,同时保护数据安全以实现安全计算。此外,设计了一个纹理嵌入层,通过低维空间中三元组样本之间的相似性度量提供联合表示。为了验证所提框架的有效性,利用两个纺织图像数据集(一个是公开的,另一个是我们收集的)构建了四个非 IID 场景,包括标签倾斜、特征倾斜和两个组合倾斜场景。实验结果证实了我们的模型的有效性,通过保持数据隐私以实现织物 IIoT 中的安全计算,在四个非 IID 场景中获得比基准更好的检测精度。
07
多目标跟踪算法
7.1
论文标题
OLT: Fast Multiple Object Tracking from UAV-captured Videos Based on Optical Flow, ACM MM 2023.
7.2
论文作者
Mufeng Yao, Jiaqi Wang, Jinlong Peng, Mingmin Chi, and Chao Liu.
7.3
论文简介
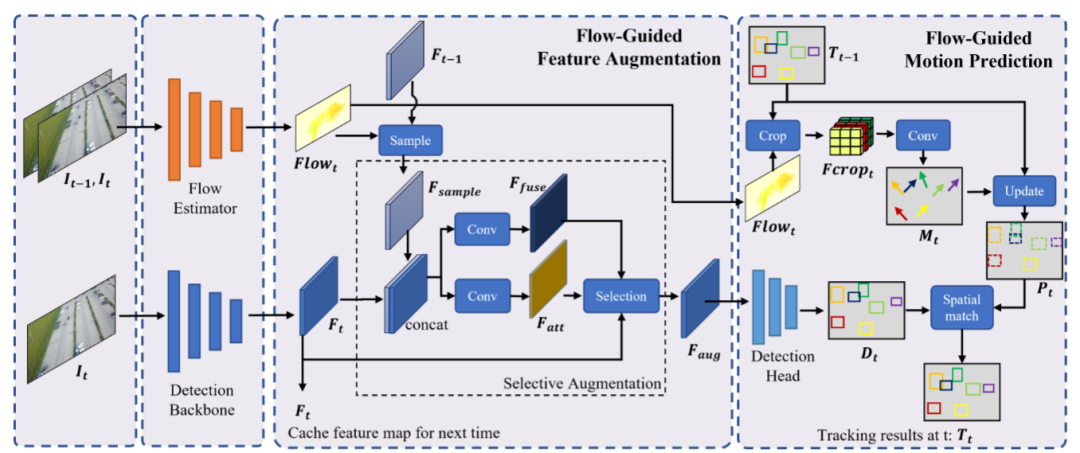
多目标跟踪 (MOT) 已在计算机视觉领域得到成功研究。然而,由于目标尺寸小、目标外观模糊以及地面目标和无人机平台的运动非常大和/或不规则,无人机 (UAV) 拍摄的视频的MOT 仍然具有挑战性。在本文中,我们提出了 FOLT 来缓解这些问题,并在无人机视图中实现快速准确的 MOT。为了兼顾速度和准确度,FOLT采用现代检测器和轻量级光流提取器以最低成本提取目标检测特征和运动特征。给定提取的光流,光流引导的特征增强旨在基于其光流增强目标检测特征,从而提高小目标的检测能力。此外,还提出了光流引导运动预测来预测目标在下一帧中的位置,这提高了相邻帧之间位移非常大的对象的跟踪性能。最后,跟踪器使用空间匹配方案匹配检测到的目标和预测的目标,为每个目标生成轨迹。在 Visdrone 和 UAVDT 数据集上的实验表明,我们提出的模型可以成功追踪具有大而不规则运动的小物体,并且在 UAV-MOT 任务中优于现有的最先进方法。
08
基于扩散模型的语音伴随手势
生成算法
8.1
论文标题MDT-A2G: Exploring Masked Diffusion Transformers for Co-Speech Gesture Generation, ACM MM 2024.
8.2
论文作者
Xiaofeng Mao, Zhengkai Jiang, Qilin Wang, Chencan Fu, Jiangning Zhang, Jiafu Wu, Yabiao Wang, Chengjie Wang, Wei Li, Mingmin Chi.
8.3
论文简介
最近,扩散Transformers领域的进展大幅提升了高质量2D图像、3D视频和3D形状的生成。然而,Transformers架构在语音伴随手势生成领域的有效性仍相对未被探索,因为此前的方法主要采用卷积神经网络(CNNs)或少量Transformers层。为弥补这一研究空白,我们引入了一种新型的用于语音伴随手势生成的掩码扩散Transformers,称为 MDT-A2G,其直接在手势序列上实现去噪过程。为了增强时间对齐的语音驱动手势的上下文推理能力,我们结合了一种新颖的掩码扩散Transformers。该模型采用了一种专门设计的掩码建模方案,以加强序列手势之间的时间关系学习,从而加速学习过程,并生成连贯且逼真的动作。除了音频之外,我们的 MDT-A2G模型还整合了多模态信息,包括文本、情感和身份信息。此外,我们提出了一种高效的推理策略,通过利用先前计算的结果来减少去噪计算,从而在几乎不降低性能的情况下实现了加速。实验结果表明,MDT-A2G在手势生成方面表现出色,其学习速度比传统的扩散Transformers快6倍以上,推理速度比标准扩散模型快5.7倍。
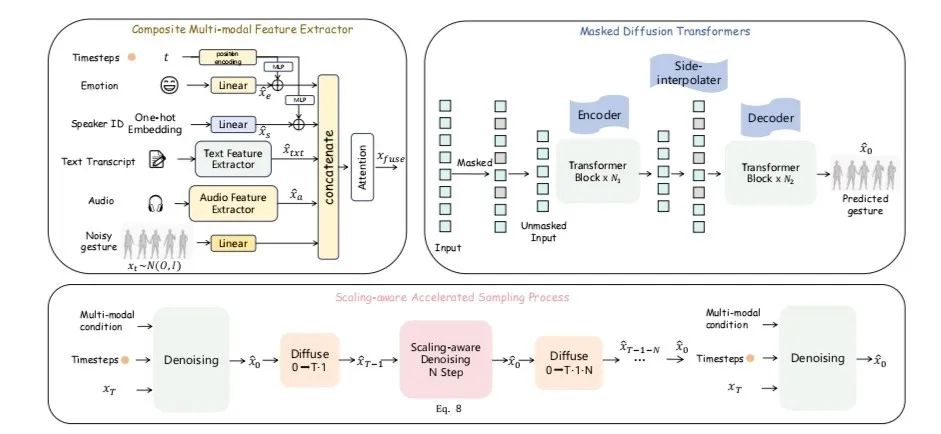
09
对比学习知识蒸馏算法
9.1
论文标题
MDR: Multi-stage Decoupled Relational Knowledge Distillation with Adaptive Stage Selection, ACM MM 2024.
9.2
论文作者
Jiaqi Wang, Lu Lu, Mingmin Chi, and Jian Chen.
9.3
论文简介
对比学习知识蒸馏(Contrastive-learning-based Knowledge Distillation,KD)的有效性重新激发了对关系蒸馏(relational distillation)的兴趣,但这些方法通常侧重于来自倒数第二层的角度信息。我们发现,利用来自中间层的关系信息可以进一步提高蒸馏的有效性。我们还发现,将距离关系信息添加到基于对比学习的方法中会对蒸馏质量产生负面影响,这揭示了角度属性和距离属性之间的隐性矛盾。因此,本文提出了一个多阶段解耦关系(Multi-stage Decoupled Relational,MDR)KD框架,配备了自适应阶段选择机制,以识别最能有效传递关系知识的阶段。MDR框架解耦了角度和距离信息,以解决它们之间的冲突,同时仍然保留完整的关系知识,从而提高了知识传递效率和蒸馏质量。为了评估所提出的方法,我们在多个图像基准(如CIFAR100、ImageNet和Pascal VOC)上进行了广泛的实验,涵盖了各种任务(如分类、小样本学习、迁移学习和目标检测)。我们的方法在各种场景下表现出优越的性能,在广泛使用的教师-学生网络对上,CIFAR-100上平均提高了1.22%,超越了现有的最先进方法。

10
主动领域适应算法
10.11
论文标题
Learning Distinctive Margin toward Active Domain Adaptation,CVPR 2022.
10.2
论文作者
Ming Xie, Yuxi Li, Yabiao Wang, Zekun Luo, Zhenye Gan, Zhongyi Sun,Mingmin Chi, Chengjie Wang, Pei Wang
10.3
论文简介
尽管在无监督或少量半监督设置下,许多努力集中于提高领域适应能力(DA),但最近主动学习的解决方案开始受到更多关注,因为它在有限的目标数据注释资源下以更实用的方式转移模型。然而,大多数主动学习方法并不是专门设计来处理数据分布之间的领域差距;另一方面,一些主动领域适应方法(ADA)通常需要复杂的查询函数,这容易导致过拟合。在本研究中,我们提出了一种简洁但有效的ADA方法,称为“按显著边际选择”(Select-by-Distinctive-Margin,SDM),该方法由最大边际损失和边际采样算法组成,用于数据选择。我们提供了理论分析,表明SDM的工作原理类似于支持向量机,存储决策边界附近的困难样本,并利用它们找到信息丰富且可转移的数据。此外,我们提出了该方法的两个变体,一个旨在自适应调整来自边际损失的梯度,另一个通过考虑梯度方向来增强边际采样的选择性。我们在标准主动学习设置下对SDM进行了基准测试,证明我们的算法在数据可扩展性方面取得了具有竞争力的结果。
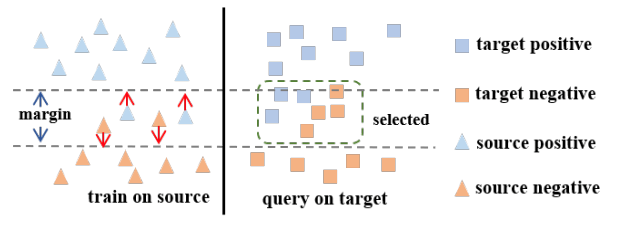
11
视觉图网络基础架构Vision Graph
11.11
论文标题
PVG: Progressive Vision Graph for Vision Recognition, ACM MM 2023.
11.2
论文作者
Jiafu Wu, Jian Li, Jiangning Zhang, Boshen Zhang, Mingmin Chi, Yabiao Wang, Chengjie Wang
11.3
论文简介
基于卷积和基于 Transformer的视觉骨干网络分别将图像处理成网格或序列结构,这对于捕获不规则物体不够灵活。虽然 Vision GNN (ViG)对复杂图像采用了图级特征,但它存在一些问题,例如邻居节点选择不准确、节点信息聚合计算昂贵以及深层过度平滑。为了解决上述问题,我们提出了一种用于视觉识别任务的渐进式视觉图 (PVG)架构。与以前的工作相比,PVG包含三个主要组件:1)渐进分离图构建 (PSGC),通过随着层数加深逐渐增加全局图分支的通道并减少局部分支的通道来引入二阶相似性;2)邻居节点信息聚合和更新模块,通过使用最大池化和数学期望 (MaxE)来聚合丰富的邻居信息;3)图误差线性单元(GraphLU)以放松的形式增强低值信息,以减少图像详细信息的压缩,从而缓解过度平滑。在主流基准上进行的大量实验证明了 PVG优于最先进的方法,例如,我们的 PVG-S在ImageNet-1K上获得了 83.0%的 Top-1准确率,比基于GNN的 ViG-S高出+0.9↑,参数减少了 18.5%,而最大的 PVG-B获得了84.2%,比 ViG-B高出+0.5↑。此外,我们的 PVG-S在 COCO数据集上比 ViG-S获得了 +1.3↑的box AP增益和 +0.4↑的 mask AP增益。

12
基于图网络的人物交互检测算法
12.11
论文标题
Relation Parsing Neural Network for Human-Object Interaction Detection, ICCV 2019
12.2
论文作者
Penghao Zhou and Mingmin Chi.
12.3
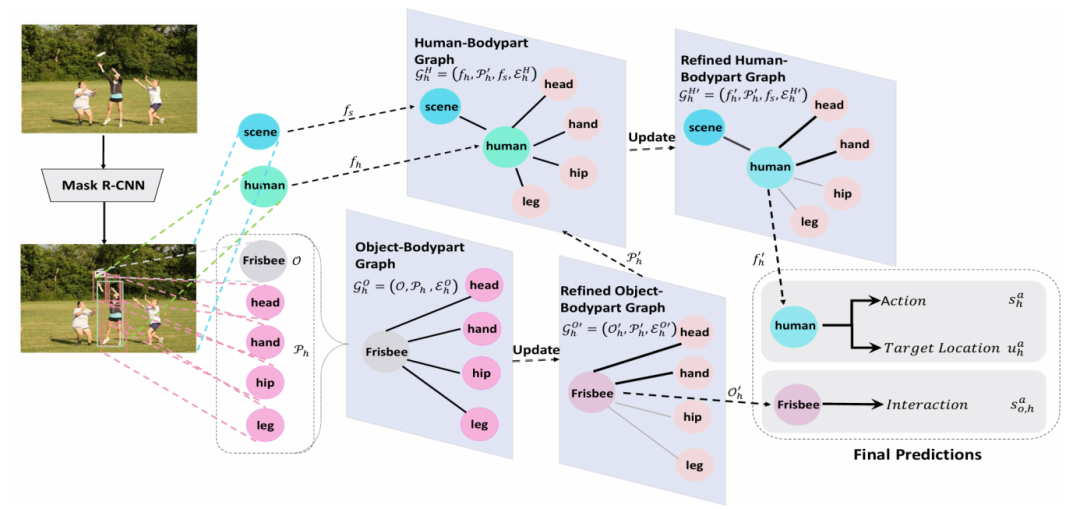
论文简介
人与物交互检测致力于推断人与物之间的三元组“人、动词、物”。本文提出了一种新型模型,即关系解析神经网络 (RPNN),用于检测人与物之间的交互。具体而言,该网络由两个图表示,即对象-身体部位图和人体-身体部位图。这里,对象-身体部位图动态捕获身体部位与周围物体之间的关系。人体-身体部位图推断人与身体部位之间的关系,并组合身体部位上下文来预测动作。这两个图通过动作传递机制相关联。提出的 RPNN模型能够在没有监督标签的情况下隐式解析两个图中的成对关系。在 V-COCO和HICO-DET数据集上进行的实验证实了所提出的 RPNN网络的有效性,其性能明显优于最先进的方法。