本文转发自上观新闻
数据如同大模型的细胞,是其生命力的来源。当大模型已经迈入分级时代,从通用大模型细分到行业大模型,再精确到企业大模型,人们对于数据的挖掘与应用是否跟上了大模型进化的速度呢?或许不然。“整个大模型还处在前牛顿时代,我们只知其然,不知其所以然。”9月5日外滩大会举办“从DATA for AI到AI for DATA”论坛,复旦大学教授、上海市数据科学重点实验室主任肖仰华在会上提出,人们目前对于数据的使用方式是非常粗放且效率低下的,“好比当年的炼金术”。
论坛现场
数据使用上的痛点是这场论坛嘉宾讨论的焦点。从目前大模型训练情况来看,数据面临的问题主要在数量和质量两方面。
最为直观的,是数据的数量。“任一模态的数据集包含多达数亿至数百亿个小文件。”中国工程院院士、清华大学教授郑纬民说,训练大模型所需的海量数据,对存储提出了巨大的挑战。以元数据管理为例,存储100亿的小文件需要管理7TB元数据。海量的数据同时也增加了时间与成本的消耗。在模型训练前,为了获得高质量的数据样本,需要对数据先进行预处理。据谷歌数据中心统计,大模型的训练中,高达30%的时间用在了数据的预处理。郑纬民说:“数据预处理开销正成为大模型训练的瓶颈之一。”
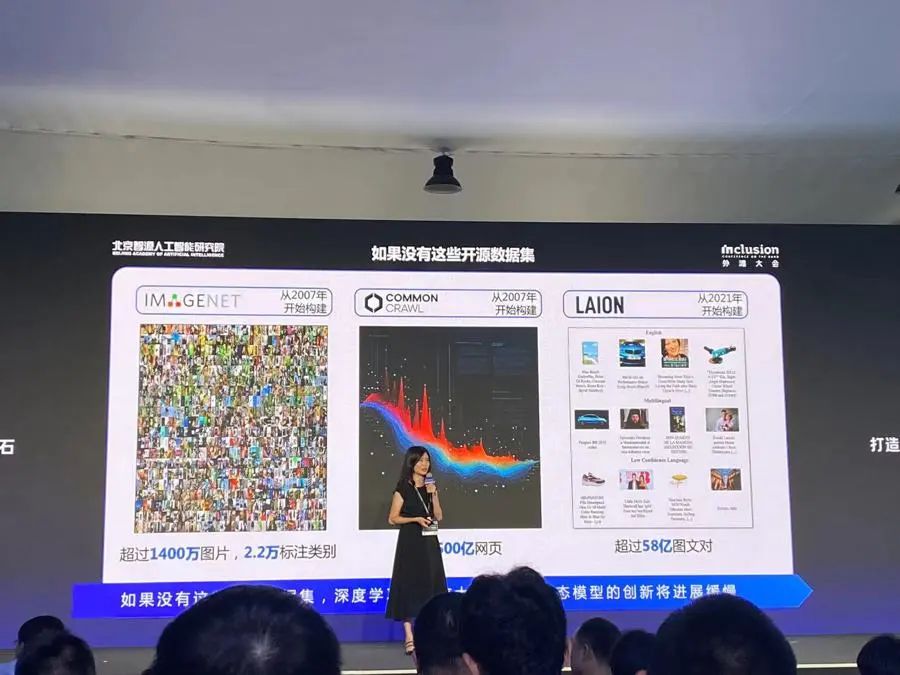
数据使用的另一掣肘是质量,这一点在中文内容上尤为突出。北京智源人工智能研究院副院长兼总工程师林咏华分享了几个数据。首先是国际数据集中的中文内容占比很少,以数据集Common Crawl为例,其中的中文数据仅占约4.8%,并且83%来源于海外中文网站。“这就导致了这些数据集训练的大模型始终是‘英文思维’,其内容的安全性、文化价值观难以保证。”林咏华说,中文内容同时还面临数据孤岛问题,全球互联网网页语言占比变化显示,中文网页占比有所下降,从2013年占比4.5%下降到2024年的1.3%。
“数据质量决定了模型的性能、成本、安全性。”林咏华说,因此包括北京智源人工智能研究院在内的多家机构正在推动数据的开源,“我们始终认为,需要一定量的高质量数据完全开源出来,去供给高校、科研团队、开发者去使用,才能不断扩充大模型,为大模型行业提供坚实的数据支撑。
肖仰华则认为,理解大模型的数据,是打开大模型“黑盒”,提升大模型可信的重要方式。“现在的大模型还经常会有幻觉,这个问题如果不解决,大模型无法真正走向千行百业。”肖仰华认为,这一过程需要小模型、智能图谱进行协同,但不管是大模型、小模型还是知识图谱,它的源头都是数据,所以数据在整个大模型技术体系中处于一个核心的基础地位。
“数据是大模型知识的来源,大模型是世界知识的编码器。”肖仰华说,一旦越过数据使用的难关,大模型将走向更深的应用,“届时大模型将真正迈入科学时代。”