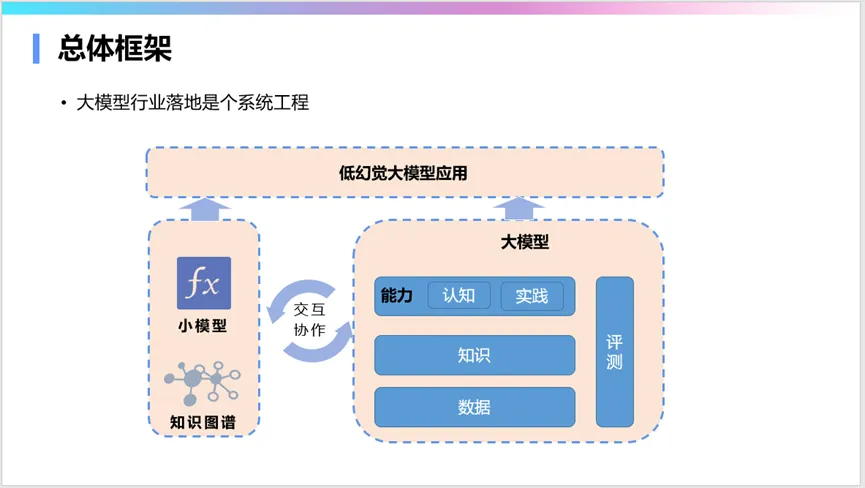
在今年的世界人工智能大会期间,由信百会研究院于7月4日下午主办的 "AI大模型行业应用趋势与创新探索"闭门研讨会上,复旦大学计算机科学技术学院教授,上海市数据科学重点实验室主任肖仰华深入剖析了大模型在行业应用中所面临的挑战与解决路径。
他指出,尽管大模型在处理开放性闲聊方面表现出色,但在复杂决策领域仍存在诸多不足,如幻觉现象、领域知识匮乏和难以控制等问题。他强调,要实现大模型在行业落地,必须加强其领域“忠实度”,通过知识注入和智能解耦重塑企业信息化架构。此外,大模型的成本效益也是关键考量,需要通过技术创新降低成本,同时提升模型的可控性和可解释性。他提出了以知识图谱为框架、大模型为引擎的行业落地模式,以及通过完善数据科学与工程来提升大模型性能的策略。他认为,大模型的可靠落地是一项系统工程,需要综合考虑评测、认知能力、交互协作及数据治理等多方面因素。
以下为肖教授现场发言内容整理。

今年,李强总理在苏州调研时明确指出,人工智能技术必须与实体行业深度融合,赋能千行百业,才能将人工智能真正发展成为先进的新质生产力。这一点对大模型尤其重要。然而,在过去一年半的时间里,大模型在行业落地过程中遇到了诸多问题。
大模型行业应用面临的挑战
一个突出的问题是,目前大部分生成式大模型仅在聊天应用中取得了良好效果,但难以胜任复杂的认知决策任务。例如,金融投资和医疗诊断等领域的决策都具有严肃性和复杂性,这些并非聊天式生成式人工智能所能胜任的。作为行业专家,需要具备专业知识、复杂逻辑推理能力、任务分解能力、规划能力以及不确定性推断能力,才能胜任这类复杂的决策任务。
生成式大模型还存在"幻觉"问题,即可能产生不准确或虚假的信息,这个问题已经困扰业界很长时间。在医疗应用中,如果给病人开具的药方或服用剂量出现错误,哪怕是单位从克变成毫克或反之,都可能造成致命后果。因此,如果不解决大模型的幻觉问题,就无法真正实现行业应用。
大模型在行业应用中还缺乏对特定领域的忠实度。虽然大模型通过互联网的通用语料学习了大量通用知识,但在应用到特定行业时,我们希望它能根据行业规范和专业知识来解决问题。然而,大模型往往倾向于使用从通用领域学到的知识来回答问题,因此缺乏对特定领域的基本忠实度。
大模型本质上是统计模型,因此面临着不可控和难以编辑的问题。随着知识的不断更新,如何高效地更新模型中的知识成为一大挑战。大多数严肃的行业应用都需要不断更新知识,如金融、医疗、司法等领域的知识都在持续变化。因此,可控性和可编辑性仍然是非常关键的。
在将大模型应用于行业时,它难以理解行业专有数据和企业私域数据。大多数行业数据具有高度专业性,如工厂中的传感器数据,需要专业知识支持才能理解。此外,许多企业内部数据反映了企业自身的业务习惯和命名规范,这些私有性很强的数据,大模型也难以真正理解。
大模型还面临成本问题。虽然大模型降低了在行业中训练不同模型的成本,但它带来了巨大的训练成本。例如,ChatGPT这样的大模型一轮训练就需要消耗6300多万美元,这不是一般企业能够承受的。此外,大模型在生成回答时速度较慢,这在大规模在线应用中可能造成严重的时间成本问题。
解决方案与发展路径
为解决大模型行业落地中的这些问题,需要采取系统性的应对措施。首先,要合理定位大模型。在商业应用场景中,大模型应被视为智能引擎,其作用是驱动企业数字化转型和高质量发展,聊天功能只是一种最低价值的应用。为了充分发挥大模型作为智能引擎的作用,需要将其与企业流程无缝融合,并与人类员工进行有效协同。

持续向大模型注入领域行业知识是解决行业问题的关键。需要将企业中使用的智能进行解耦,将智能分解为知识、能力和价值三个维度。只有进行这样的解耦,才能利用大模型作为新的智能引擎,重塑企业的信息化和数字化形态。
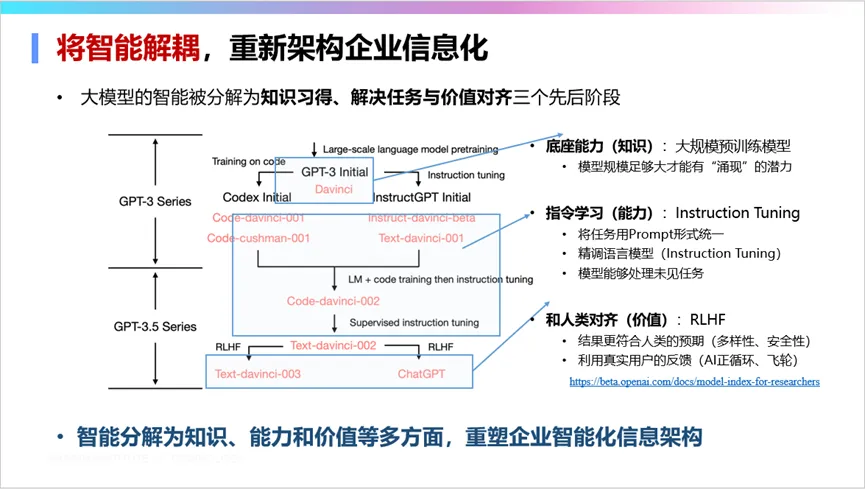
将企业流程进行解耦也很重要。一些世界500强企业已经开始用大模型重塑整个企业的数字化架构。当前的数字化系统往往较为臃肿,难以实现敏捷性目标,无法适应快速变化的需求。因此,重塑信息化架构成为必要。这个重塑过程中,关键是将流程解耦为提示、生成和评价三个基本环节。其中,生成环节可以交给大模型,而人类则负责提示工作和评价选择工作。

在探索大模型的行业落地模式时,不应局限于简单的聊天界面。一个更有效的ToB行业落地模式可能是:使用大模型进行离线处理,结合知识图谱组织信息,再通过小模型提供在线服务。这种方式可以充分利用大模型的能力,同时保证服务的可控性和效率。

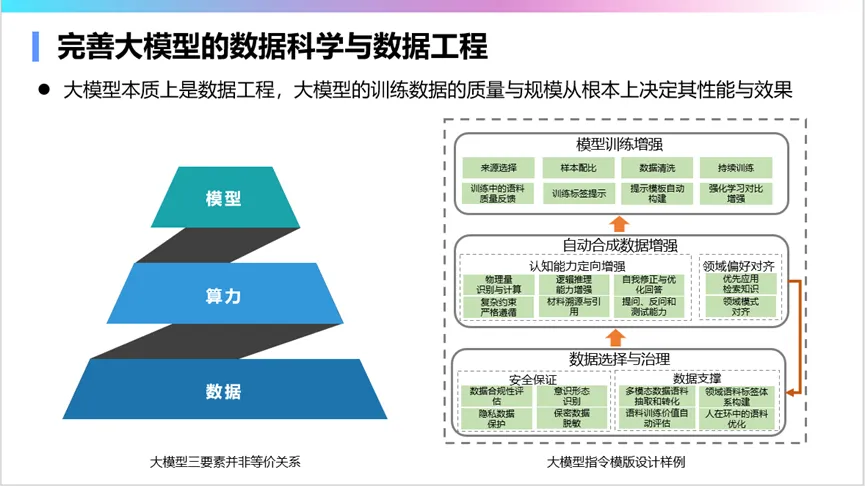
推动大模型向行业应用发展时,需要注重几个关键方面。首先是完善大模型的数据科学和数据工程。大模型落地的本质是数据工程,80%的资源和工作量都花在了数据整理上。这包括收集、汇集、清洗、转换数据,以及构造指令数据等。在这个过程中,要重视数据规模的重要性,同时也要注重数据质量。最近的研究表明,使用5%的优质指令可能比使用100%的普通指令效果更好。
此外,还需要注重特殊类型数据的使用。例如,为了激发大模型的某些特定能力(如反思、逻辑推理等),需要合成相应的数据。建立行业大模型训练语料和指令集的评测标准和筛选机制也很重要,这是目前整个行业的一个痛点。事实上,我们的一些学科设置、课程设置,对这个事情很有意义。当前一些头部企业,正在合作开展利用人类的教育学理论,积极建立大模型行业语料的评测标准和筛选机制,我们需要尽快建立起以数据为中心的大模型研发体系。

大模型的研发应该以数据为中心,而不是以模型为中心。目前,大模型在模型方面的创新相对有限,关键在于数据的质量和数量。很多大模型只有知识,但缺乏真正的理性思维能力。为了提升大模型的强思维能力和强理性能力,需要大量合成模拟人类思维过程的数据。
注重大小模型协同也是降低成本的关键。在很多情况下,可以使用大模型去增强小模型,或者用大模型调教小模型。小模型在训练成本、使用成本、推理速度,以及可控性、可编辑性、可理解性和可解释性等方面,都具有大模型所不具备的优势。因此,大小模型的协同使用才能真正创造价值。很多传统任务,比如问答系统,很多人在做,实际上并不是所有的问题都需要用大模型来解答,80%的常规问题小模型就可以解决,“杀鸡未必非得用牛刀”,20%需要用牛刀的问题再用大模型,所以大小协同一定是行业落地的关键。
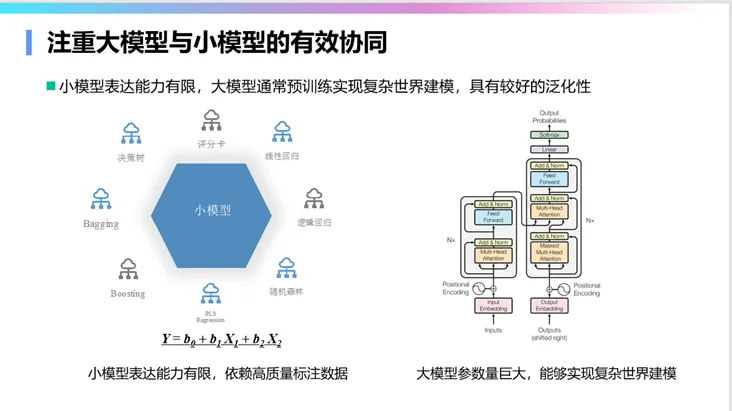
大模型与传统专家知识的协同,特别是与知识图谱的协同,也很重要。知识图谱中的知识是可理解、可解释和可控的,而大模型中的知识则难以理解和控制,所以一定要二者协同。两者协同的基本方式有三种:使用知识图谱中的知识挖掘思维链,增强大模型的思维方式;将知识图谱作为知识来源,用检索增强方法改善大模型的生成结果;利用知识图谱中的知识约束和检验大模型生成的结果。
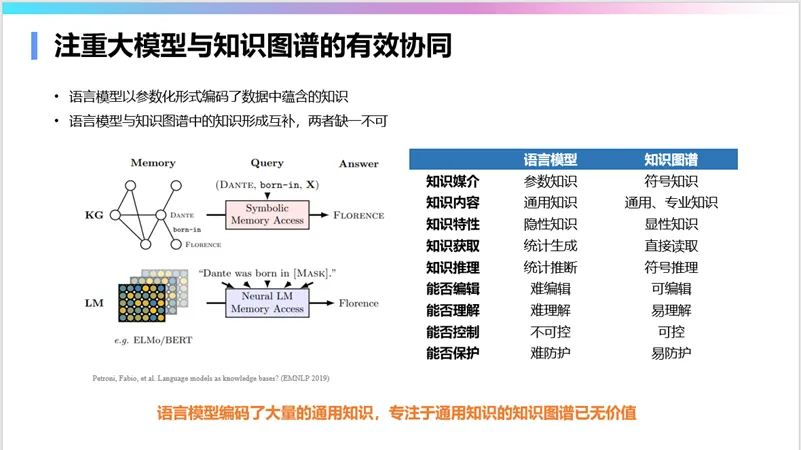
建立大模型的数据治理体系也很重要。这是一个双向的过程:一方面,大模型的训练语料需要从合规、安全、隐私、版权、偏差等方面进行治理;另一方面,大模型也可以用来支持数据治理工作,如验证知识库中知识的正确性,或清洗规范化数据等。

解决大模型的幻觉问题是行业落地的关键。这需要从预训练语料的准备、指令集的构造、检索增强、应用到事后检验等多个环节入手,系统性地提升模型的知识准确性。例如,提升模型的引经据典能力、自知之明能力、置信度表达能力等,都有助于降低幻觉的发生。
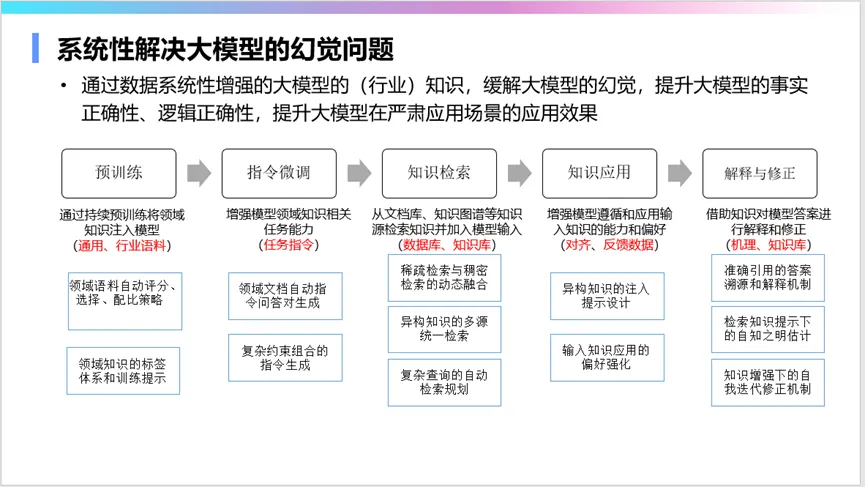
此外,还需要系统性地提升大模型的认知能力。这包括增强复杂指令理解能力、数量推理能力、单位换算能力、逻辑推理能力等。这些能力对于大模型在金融、医疗等行业的应用至关重要。
建立健全的评测体系也很重要。需要从多个维度对大模型进行评测,包括面向领域的评测、面向知识的评测、面向能力的评测、面向智商的评测,以及面向情商的评测等。

最后,推进智能体的落地也是大模型行业应用的重要方向。智能体是行业落地大模型的重要产品形态,能够完成很多常规工作的自动化。这需要提升大模型的规划能力、约束理解能力、角色设定忠实度等。
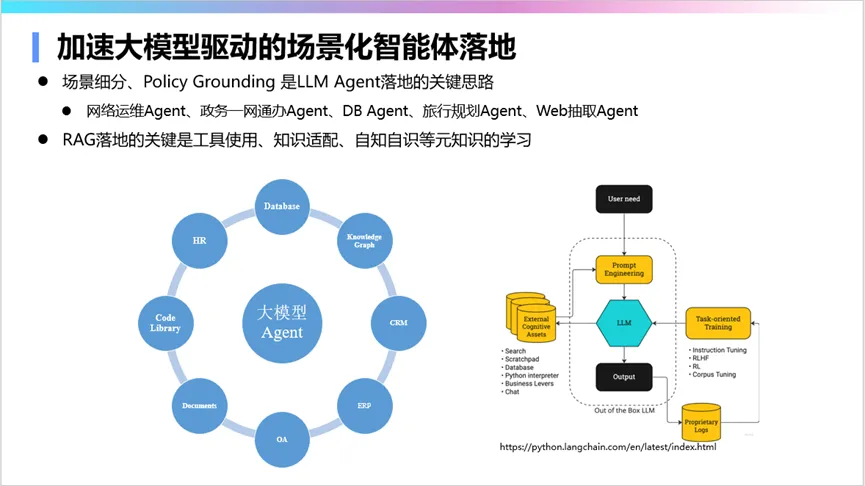
总的来说,大模型的行业应用体系框架已经很成熟。不仅要完善大模型本身,还需要从数据、知识、能力三个维度去优化,同时做好评测工作,协调大模型与小模型、知识图谱的协同,最终实现低幻觉的行业应用。大模型行业应用的本质是低幻觉,把这件事情做好,才能够真正推动大模型在行业应用。大模型是推动各行各业高质量发展的实实在在的先进生产力,我们必须抓住这个新的发展机遇。