本文转发自上戏艺管熊贇教授,数据科学重点实验室副主任
2024年12月2日下午,熊贇教授受上戏“艺管精英计划”邀请于上海戏剧学院华山红楼,就“AIGC:概念、应用与发展”主题发表精彩演讲。熊教授以其深厚的学术底蕴和对AIGC领域的深刻见解,为在场师生带来了一场内容丰富、启发思考的讲座。演讲不仅深入探讨了AIGC的基本概念,还涉及了其在多个领域的应用前景,并对其未来发展进行了前瞻性的分析。

上戏董峰教授主持
讲座伊始,熊贇教授借助两张图片引出主题。首张为2022年9月斩获数字艺术类奖项的《太空歌剧院》,它由AI绘图制作并使用Photoshop进行润色——这表明在GPT和AIGC火爆之前,AI已经具备绘画能力。第二张图片展示了一段由Sora生成的视频,仅需简单提示词即可生成一分钟的视频,由此表现AI从文字至图像再至视频的显著进步。基于此,熊赟教授提出了一些大家常有的疑问,如:AI能生成何种内容及其原理?所谓“喂给AI的数据”与“多模态数据”是什么?AIGC又是何物?如何应用现有的AIGC工具?它们的效果如何?

熊贇教授演讲现场
01数据与数据模态
紧接着,熊贇教授向大家介绍了数据的基本概念、多样模态以及其在人工智能领域中的应用。首先,数据是在各种活动过程中不断信息化产生的,例如走廊摄像头、小程序签到、手机拍照以及刷小红书等行为。
在我们的数据空间,即计算机中,包含数字、字母、图像、声音和代码等各种形式,它们均被视为数据。同时,处理这些数据的计算机程序本身也成为计算机数据的一部分。因此,数据实质上是网络空间中的唯一存在。数据虽然无形且无法直接感知,但其背后却蕴含着巨大的价值和潜力,成为重要的数据要素。
这主要归功于数据的以下性质:第一,数据具有物理属性。尽管数据看不见摸不着,但它实际上存储在硬盘、光盘、软盘等物理介质上。这些数据以二进制形式(如1010)储存在磁盘的特定磁道中,占据一定的物理空间。因此,数据作为资产的价值依赖于其物理存储的支持。第二,数据具有存在属性。虽然数据本身不可见,但通过软件和IO设备(如显示器和投屏设备),可以将其转化为可感知的形式。这使得我们不仅能够存储数据,还能通过视觉和触觉感知其存在。第三,数据具有信息属性。对于不同的人来说,相同的数据可能具有不同的信息和价值。AI算法能够学习数据中的不同价值,并将其呈现给不同的用户,这正是算法的魅力所在。第四,数据具有时间属性。这是一个较为复杂且尚未完全明确的性质。
数据可以记录过去的行为和事件,但其“时间”概念在虚拟空间中并不完全等同于现实世界的时间。例如,实物可能会过期,但数据本身却可以长时间保存,甚至50年后仍然存在,只是可能由于技术限制而无法显示。
数据的模态多种多样,常见的模态包括文本、图像、视频、音频等。对于算法而言,不同模态的数据需要采取不同的处理方式。多模态学习,或者说现在的 AIGC生成技术的发展经历了逐步演进的过程。最初,机器学习技术尚处于起步阶段,效果有限,类似于人类幼儿的牙牙学语阶段。那时,算法只能识别简单的图像并给出基本的单词描述,如将一张图片识别为“Dog(狗)”、“Computer Keyboard(电脑键盘)”。随着技术的进步,算法逐渐变得“聪明”起来,如同小朋友逐渐学会连词造句。此时,算法不仅能识别图像中的元素,还能生成简单的句子进行描述,例如:“This is a dog resting on a computer.(这是一只狗在电脑上休息。)”进一步发展后,AI算法的能力显著增强,变得妙语连珠,能够生成更加丰富和有趣的内容。例如,它能巧妙地运用形容词进行细致入微的描述,如“A white shaggy beautiful dog laying its head on top of a computer keyboard.(一只毛茸茸的白色漂亮狗把头放在电脑键盘上。)” 换言之,算法的能力从基本的识别功能发展到能够讲述一个完整的看图说话故事,甚至能够阐述更具趣味性和深度的内容。这就是所谓的多模态学习在“学什么”。当然,这里所举的例子仅涉及从图像模态到文本模态的转换,而多模态学习的实际应用范围远不止于此。

熊贇教授介绍数据集的发展
那么,究竟是什么原因使得人工智能算法能够实现如此强大的功能呢?在此过程中,科学家们构建了大量的数据集,这些数据集主要由成对的图片和相应的标签组成。尽管这一过程看似简单,但在2002年,仅有5000张带有标签的图片就足以推动众多算法的发展。最具代表性的例子是2009年,由李飞飞教授提出的lmageNet数据集。这一数据集的出现使得图片数量和标签数量大幅增加,从而促使算法的能力得到显著提升。
因此,我们可以观察到自2009年之后,算法的性能逐渐增强。最初算法的性能相对较弱,识别错误率高达近30%。然而,在2009年lmageNet数据集问世后,算法不断优化和改进。到了2015年,算法在识别猫狗等图片方面的表现已超越了人类。当然,这里所讨论的是通用场景下的表现。
在复杂场景中,算法的性能仍有待提高。随着数据的不断积累,我们逐渐认识到大数据和人工智能之所以强大,正是因为拥有了海量数据的支持。那么,既然存在如此高效的方法,我们能否将其应用于更具趣味性和价值的领域呢?如何将这些技术转化为实际生产力呢?
于是,有人开始尝试将AI技术应用于为图片生成标题与个性化风格文案生成等领域。例如,在电商平台上,AI可以根据不同达人的风格、不同用户的喜好为其生成个性化的文案。除了为单张图片生成描述外,AI还可以为一组(多张)图像生成一段连贯的描述。AIGCAIGC(AI-Generated Content),即人工智能生成内容,涵盖文本生成、图像生成、音频生成、视频生成以及图像、视频、文本之间的跨模态生成。例如,最早的AIGC应用之一便是翻译,它属于同一模态内的内容生成,即文本到文本的转换,如从中文翻译成英文或法文等。此外,AIGC还可以实现文本输出生成图像、看图说话(包括添加更多描述或以诗歌形式表达)等功能。同时,AIGC还能协助编写代码、翻译代码注释以及在不同编程语言之间进行代码翻译。因此,有了AIGC技术,不同模态之间的转换变得更加容易。
02人工智能与大语言模型
随后,熊贇教授深入浅出地阐述了人工智能的概念、发展与应用,明晰区分了机器学习与深度学习的区别。她以实际案例讲解了大语言模型的原理、训练过程、优化方法,并探讨了其在现实场景中的独特优势与不可避免的局限,为听众呈现了一幅清晰的人工智能技术图谱。
人工智能(Artificial Intelligence, Al)旨在使机器具备类似人类的智能,能够进行思考。AI的概念始于1956年,当时美国的一些专家提出了让计算机理解和使用人类语言的目标。经过多次迭代和发展,AI技术在诸如IBM深蓝战胜国际象棋冠军(1997年)和谷歌的AlphaGo战胜围棋棋手李世石(2016年)等方面取得了显著成果。近年来,随着大数据和算力的飞速发展,大模型逐渐崭露头角,为人们所熟知。
AI之所以能够取得如此显著的成果,主要归功于数据量的增加、算力的提升以及算法的不断优化。AI技术最初应用于数据点分类,如将客户分为不同信用等级。随后,AI开始学习识别图片中的物体,如猫狗等,并逐渐扩展到识别更复杂的场景。此外,AI还广泛应用于推荐系统,通过对人群进行划分和性格特点分析,为用户提供个性化推荐。除了内容生成外,人工智能在商业领域的应用也非常广泛。例如,今日头条、抖音和小红书等平台利用推荐算法为用户提供个性化内容。
然而,这种推荐系统也存在一定的缺点,如可能导致用户陷入信息茧房。机器学习与深度学习机器学习和深度学习是相关但有所区别的概念。简单来说,深度学习是机器学习的一种但更侧重于使用复杂神经网络模型来处理数据。传统机器学习依赖于特征提取和手动设计特征,而深度学习则通过大量数据自动学习特征表示,类似于人类大脑的学习方式。
大语言模型的核心方法是基于“词语接龙”的原理。例如,当提到“上海戏剧“时,大多数人会想到“学”字,因为在日常接触的文本中,“上海戏剧学院”的出现频率较高。GPT等大语言模型通过学习大量文本数据,根据上下文预测下一个词,从而实现语言生成。大语言模型的训练分为两个阶段:预训练和微调。在预训练阶段,模型自学大量无标签文本,学习语言的基本规律。然后,在微调阶段,模型通过人类提供的有标签数据进行训练,以提高其准确性和泛化能力。这一过程类似于一个学生的学习过程,先自学,然后接受老师的指导和测试。不同的大语言模型性能差异主要源于训练数据和微调过程的不同。例如,专门针对某个领域(如艺术管理)训练的模型,在该领域的表现可能会优于其他领域,因为其训练数据更专注于该领域。
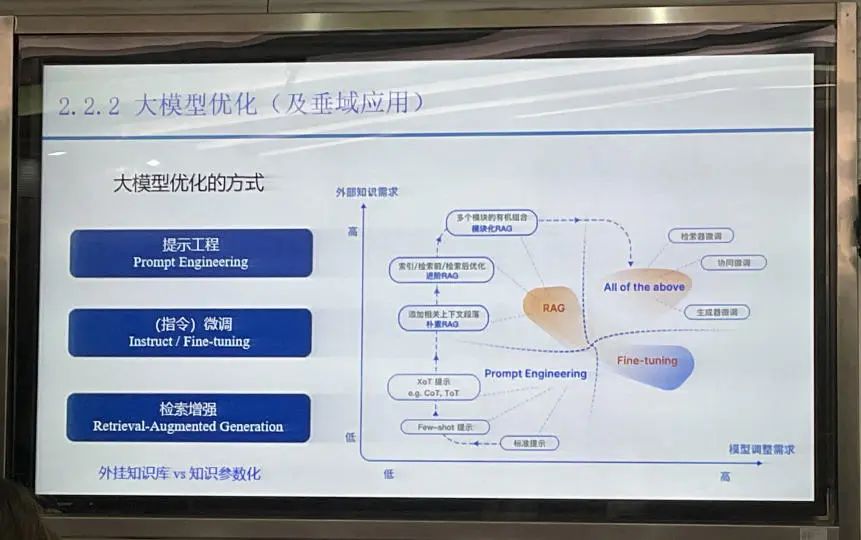
大模型优化方式与垂类应用
大模型优化的方式主要有三种:提示工程(Prompt Engineering)、(指令)微调(Instruct /Fine-tuning)、检索增强(Retrieval-Augmented Generation)。
在大语言模型的应用中,我们可以通过提示学习(Prompt Learning)来优化模型的回答。例如,通过给模型提供特定的角色、上下文或其他参考信息,引导模型生成更符合需求的回答。例如,当向其询问“GPT模型的原理”时,我们可以指定不同的角色来获得不同风格的回答。若以小学生的角度提问,模型会采用更通俗易懂的解释方式;而若以戏剧学院学生的角度提问,模型则会运用与专业相关的表达方式来回答。提示学习的优势在于,它无需重新训练一个专门针对特定领域的模型,从而节省了大量资源和时间。
大模型不仅可以进行自然语言处理任务,还能在一定程度上调用程序。然而,它并非在所有情况下都能完美运行。例如,在查询路线方面,大模型可能无法提供准确的导航信息。因此,作为使用者,我们不应完全依赖大模型而忽视小模型的作用。实际上,小模型在许多场景下仍具有很大优势,如使用导航软件查询路线等。
目前,最流行的做法是将大模型与小模型相结合,让大模型负责处理复杂的任务,而小模型则负责处理专业性较强的任务。这样既能发挥大模型的潜力,又能充分利用小模型的优势。除了提示学习外,还有一种优化大模型的方法,即检索增强(Retrieval-Augmented Generation)。这种方法是通过为大模型外挂一个知识库来实现的。通过这种方式,大模型可以在需要时从知识库中检索相关信息,从而提高其回答的准确性和可靠性。这种方法在处理复杂问题和专业领域问题时尤为有效。
在此之后,熊贇教授借助实例,详细展示了国内外较热门的AIGC工具及其各自的优缺点,包括GPT- 4o、豆包、Kimi、文心一言、Stable Diffusion、midjourney、智谱清言、即梦AI等。并向大家介绍了AIGC在多个现实领域的应用,同时也指出了其面临的风险与局限性。首先,从2015年至2022年,AIGC产业图谱呈现出快速发展的态势。七年间,涌现出众多AI工具。而从2023年至2024年,AIGC的发展更是迅猛,一年内出现了大量且多样的AIGC工具。这些工具涵盖了文本、图像、音频、视频等多个维度,为诸多行业提供了强大的支持。
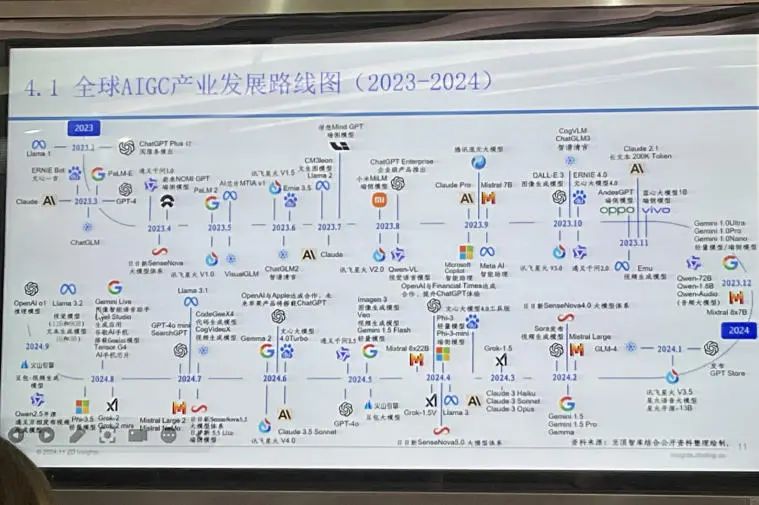
全球AIGC产业发展路线图(2023—2024)
以米哈游为例,该公司于2021年9月9日发布了专为游戏领域设计的生产式人工智能大模型。这一模型的综合度更高,难度也更大。此外计算机学会还围绕黑悟空游戏进行了探讨,分析了其中所使用的AIGC技术。除了感性应用场景外,AIGC在理性应用场景中也发挥着重要作用。例如,在数据分析方面大模型可以分析Excel文件,帮助用户完成计算任务。在金融风控领域,AIGC可以帮助监管机构识别异常交易行为,如通过分析交易数据来发现潜在的市场操纵行为。此外,AIGC还可用于医学影像报告生成、蛋白质结构预测等理性分析任务。然而,AIGC也存在一定的局限性。首先,由于其基于概率生成内容,可能会出现幻觉,即生成与实际情况不符的内容。其次,AIGC在数据安全和隐私方面也存在风险,如可能被用于生成虚假信息或侵犯他人隐私。此外,AIGC还可能受到训练数据的偏见影响,从而产生歧视性或不公平的结果。
04结语
讲座结尾,熊贇教授强调,在AIGC的应用过程中,领域知识和专业知识的重要性不言而喻。只有具备相关领域知识和专业知识的人才才能更好地利用AIGC工具创造出更优质、更优秀的作品。因此,同学们应该注重培养自己的领域知识和专业知识,以便更好地应对AIGC带来的挑战和机遇。

讲座后师生合影