导 语
近期,数据科学重点实验室陈思明老师带领的可视分析与智能决策实验室(FDUVIS)在国际顶级期刊和会议上发表了多篇论文。其中,4篇发表在IEEE TVCG期刊(3篇由IEEE PacificVis 2025 Journal Track接收),1篇被ACM CSCW 2025会议接收。这些成果展示了陈思明老师团队在可视化与可视分析等领域的前沿研究进展。
1面向自动任务拆解与执行的大模型驱动轻量化可视分析框架LightVA
题目:LightVA: Lightweight Visual Analytics with LLM Agent-Based Task Planning and Execution作者:Yuheng Zhao, Junjie Wang, Linbin Xiang, Xiaowen Zhang, Zifei Guo, Cagatay Turkay, Yu Zhang and Siming Chen(复旦大学、华威大学、牛津大学)
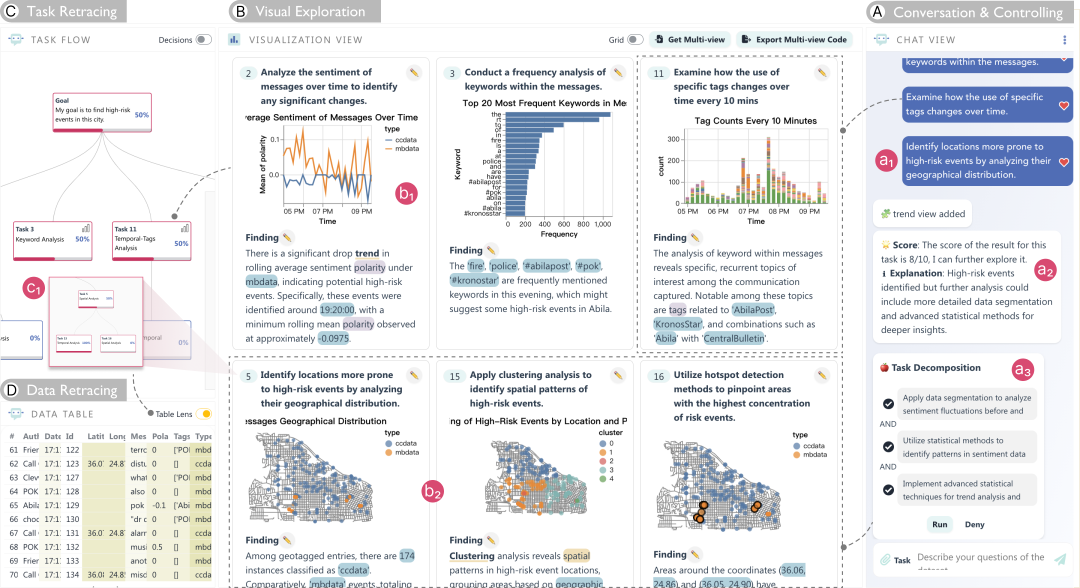
图1. LightVA将用户和智能体的协作分为三个阶段:任务推荐、任务分解、任务执行。基于框架实现的系统原型包含四个视图。用户可以在 (A) 聊天视图中与 LLM 进行交互并控制规划过程。在 (B) 可视化视图中探索由LLM 生成的单个或多个链接的可视化和洞察。在任务流视图 (C) 监控和管理可视化任务规划过程。用户可以在数据表视图 (D) 中查看数据探索覆盖度。
介绍:可视分析通常要求分析师根据洞察动态创建可视化,并在此基础上提出新任务以推动分析进程。为了实现这一目标,分析师需具备数据处理、分析和使用可视化工具的综合能力。然而,分析过程的复杂性和高门槛往往降低了分析效率,亟需一种智能化、简化的可视分析方法。近年来,大型语言模型(LLMs)作为智能代理得到了广泛应用,凭借其动态任务规划和工具使用能力,为提升可视分析效率和多功能性提供了新的可能。本文提出了LightVA,一个轻量级的可视分析框架,通过人机协作支持任务分解、数据分析和互动探索。我们的框架帮助用户将高层次的分析目标转化为低层次的任务,生成可视化并提炼洞察。具体而言,我们设计了一种基于LLM代理的任务规划与执行策略,涵盖规划者、执行者和控制者三种智能角色:规划者负责任务推荐与分解,执行者处理数据分析、可视化生成和多视图组合,控制者则协调二者的互动。在此基础上,我们开发了一个混合用户界面系统,包括任务流图用于监控任务规划进程、可视化面板支持数据互动探索、以及聊天视图通过自然语言指令引导模型。最后,本文通过一个VAST Challenge案例的使用场景与专家调研,验证了该方法的有效性。
该论文已发表于IEEE Transactions on Visualization and Computer Graphics (TVCG) 2024。IEEE TVCG是中国计算机学会(CCF)推荐的A类国际学术期刊。它的编辑委员会致力于发表计算机图形、可视化和虚拟现实方面的重要研究成果和最先进的开创性论文。论文链接:https://ieeexplore.ieee.org/document/10753451
2交互式大模型驱动智能体的社交媒体行为仿真模拟SimSpark
题目:SimSpark: Interactive Simulation of Social Media Behaviors
作者:Ziyue Lin, Yi Shan, Lin Gao, Xinghua Jia, Siming Chen(复旦大学)
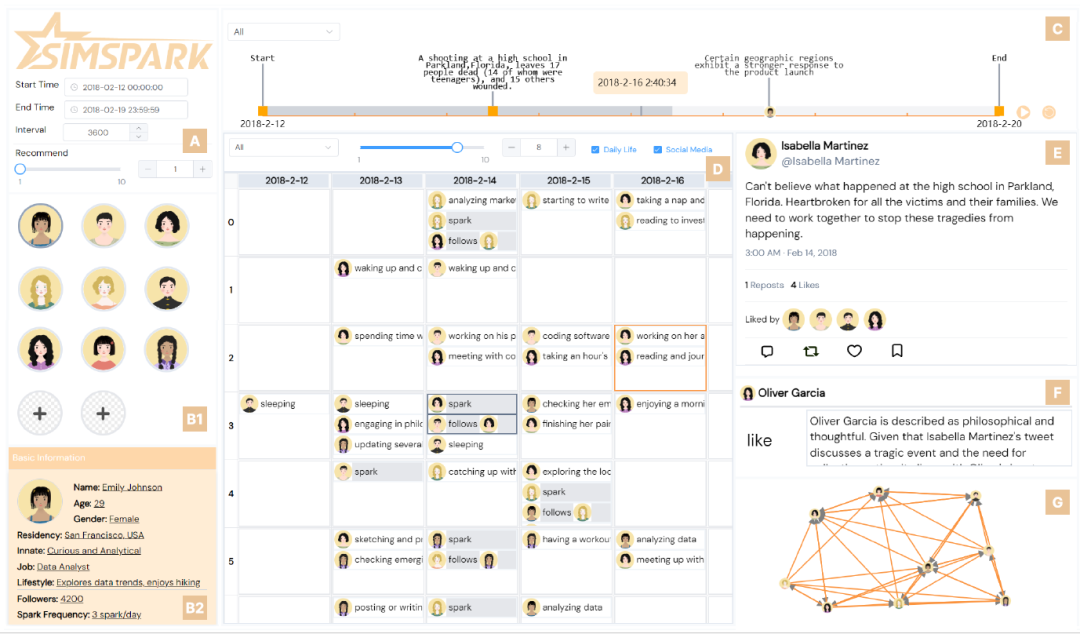
图2: SimSpark 的界面。(A) 设置面板允许用户配置环境参数。(B1) 头像视图显示智能体的头像。(B2) 基本信息视图允许用户配置选定智能体的人口信息和社交习惯。(C) 时间轴显示公共事件和模拟进程。(D) 日历视图显示智能体的行为。(E) Sparkle 视图显示模拟的社交媒体。(F) 推理视图显示代理模拟社交媒体行为背后的原因。(G) 可在视图中切换 “关注网络 ”和 “隐藏推理”。关注网络显示智能体之间的关注关系。隐藏推理显示智能体不采取行动的原因。
介绍:理解用户在社交媒体上的行为有助于我们更好地理解虚拟平台如何影响社会,并增强决策者的能力。模拟社交媒体行为为捕捉社交媒体行为模式、测试假设和预测各种干预措施的效果提供了强有力的工具,有助于加深对社交媒体环境的理解。此外,它还能克服利用真实数据进行分析的困难,如数据可访问性、伦理问题以及处理大型异构数据集的复杂性。然而,研究人员和利益相关者需要更灵活的平台,通过模拟不同的场景和角色来研究不同的用户行为,而这一点目前还无法实现。因此,本文介绍了 SimSpark,这是一个包含模拟算法和交互式可视化界面的交互系统,能够创建具有可定制角色和社交环境的小型模拟社交媒体平台。我们要应对三大挑战:生成可信的行为、验证仿真结果以及支持生成和结果分析的交互式控制。我们引入了一个仿真工作流程,利用大语言模型生成可信的智能体行为。交互界面可实现实时参数调整和过程监控,以便自定义生成设置。此外,我们还设计了一套可视化和交互方式,以显示模型的输出结果,供进一步分析。通过案例研究、定量模拟模型评估和专家访谈来评估其有效性。
该论文被ACM SIGCHI Conference on Computer-Supported Cooperative Work & Social Computing (CSCW 2025)接收。CSCW (ACM Conference on Computer Supported Cooperative Work and Social Computing) 是人机交互与普适计算的方向的顶级会议,中国计算机学会(CCF)推荐的A类国际学术会议。
3大模型驱动的时序可视化自动洞察提取与故事叙述ChartInsighter
题目:ChartInsighter: An Approach for Mitigating Hallucination in Time-series Chart Summary Generation with A Benchmark Dataset
作者:Fen Wang, Bomiao Wang, Xueli Shu, Zhen Liu, Zekai Shao, Chao Liu, and Siming Chen(复旦大学、郑州大学)

图3:在ChartInsighter中,用户输入visualization specification和数据后,Uni-Insighter和Multi-Insighter分别生成单维和多维的洞察,并由Writer初步生成图表描述。Multi-Insighter与Writer协同工作,通过迭代优化图表描述。进入self-consistency阶段后,系统进一步检查并修正潜在的幻觉。Prompt Template展示了每个步骤的输入、提示和输出。
介绍:有效的图表描述能够为决策者节省大量的时间和精力,帮助他们迅速准确地理解图表所传达的信息。目前,许多研究已利用大语言模型(LLM)实现自动化图表描述生成,但由于LLM在语义分析和计算推理方面存在不足,常常导致生成结果出现幻觉。为了解决这一问题,我们首先整理并总结了图表描述的关键组成部分,并统计归纳了在生成图表描述时常见的幻觉类型。在此基础上,我们提出了ChartInsighter,一种基于multi-agent协作的自动化时序数据图表描述生成方法,有效减少图表描述生成过程中的幻觉现象。我们设计了外部数据分析模块,以缓解特定类型的幻觉,辅助描述的生成。此外,我们还实现了一种自一致性方法来验证和修正生成的描述。为了支持后续的效果评估,我们构建了一个高质量的图表和描述的Benchmark,对幻觉类型及其频率进行了逐句标注,从而为未来的幻觉减少研究提供了评估工具。通过使用该Benchmark进行评估,我们的方法在多个指标上超越了现有的最先进模型,并且我们的图表描述幻觉率最低,成功减少了多种幻觉现象并提高了描述的质量。
该论文被IEEE Pacific Visualization Symposium (PacificVis 2025, TVCG Journal Track)接收。PacificVis由IEEE可视化和图形技术委员会(VGTC)主办,旨在促进可视化研究人员和从业人员之间加强交流,特别是在亚太地区。在原创性、严谨性和重要性方面表现出卓越质量的论文将发表在IEEE可视化与计算机图形学顶刊(TVCG)的特刊上。
Benchmark: https://github.com/wangfen01/ChartInsighter
4历史可视化分类标注方法VisTaxa
题目:VisTaxa: Developing a Taxonomy of Historical Visualizations
作者:Yu Zhang, Xinyue Chen, Weili Zheng, Yuhan Guo, Guozheng Li, Siming Chen, Xiaoru Yuan(牛津大学、北京大学、复旦大学、北京理工大学)
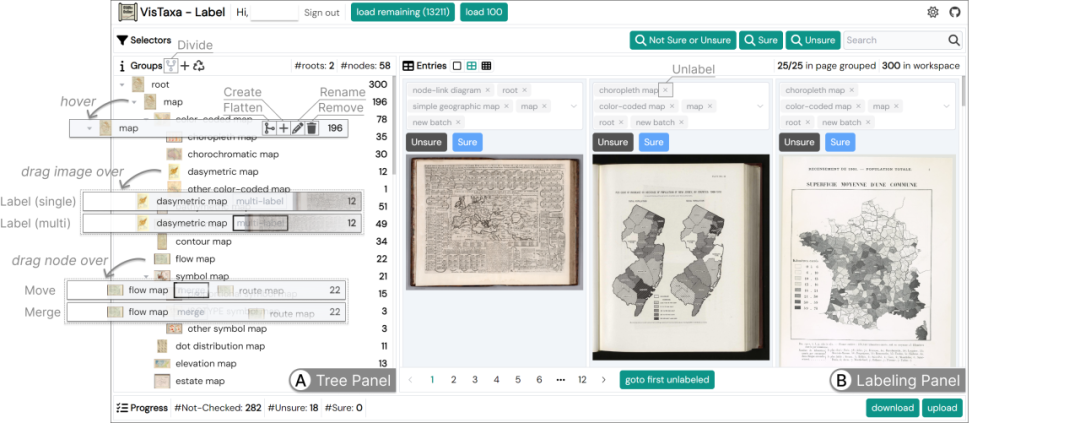
图4: VisTaxa 用于分类标注的界面:(A) 树面板显示分类树。在树面板中,编码者可以通过操作编辑分类树,例如创建、重命名、拆分、删除、移动分类节点,以及合并两个分类节点。编码者还可以通过拖动图像并将其放到分类节点上,将图像分配到该分类中。(B) 标注面板显示分类标签。在标注面板中,编码者可以编辑每张图像的分类标签。
介绍:VisTaxa将可视化工具用于质性编码,总结了前计算机时代的老可视化的分类体系。该研究针对以往分类体系集中于当代可视化设计的不足,通过引入迭代编码流程和机器辅助分类,将系统化而高效地总结了老可视化的设计空间。研究团队进一步利用编码流程得到的数据标注,对13,000余张历史可视化图像的设计类型进行了分类预测,为数据可视化发展史的研究提供了重要参考。该工作展现了质性分析在数字人文研究中的应用潜力,为可视化与历史领域的跨学科研究提供了新范式。研究成果不仅为后续研究提供了系统性的编码框架,还为后续开发老可视化图像的检索与分析工具提供了技术支撑。该工作被Pacific VIS 2025接受,并将同时发表于IEEE TVCG。
该论文被IEEE Pacific Visualization Symposium (PacificVis 2025, TVCG Journal Track)接收。
5沉浸式类脑可视分析方法DTBIA
题目:DTBIA: An Immersive Visual Analytics System for Brain-Inspired Research
作者:Jun-Hsiang Yao, Mingzheng Li, Jiayi Liu, Yuxiao Li, Jielin Feng, Jun Han, Qibao Zheng, Jianfeng Feng, Siming Chen(复旦大学,香港科技大学)
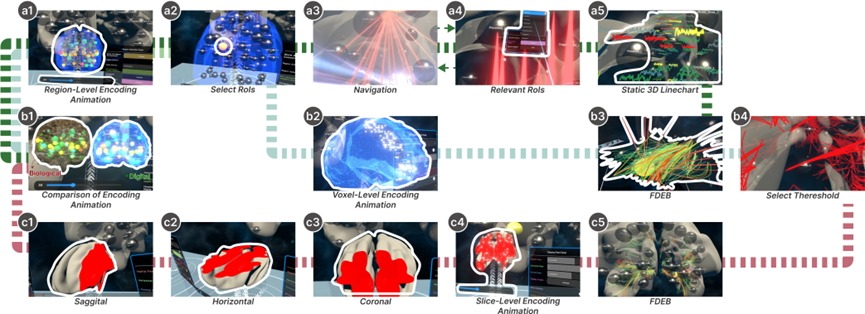
图5: DTBIA 的三种探索路径:深绿色路径从时间滑块识别脑活动峰值,选择感兴趣区域并导航至大尺度模型进行连接优化;浅绿色路径专注体素层级,通过编码动画和阈值调整优化高活动体素;红色路径从切片层级探索,结合矢状、水平和冠状面定位体素并优化连接。
介绍:数字孪生脑(DTB)是一个结合脉冲神经元的先进人工智能框架,旨在模拟复杂的认知功能和协作行为。然而,DTB数据的高维度、动态变化以及复杂的空间结构,使得现有的可视化工具难以支持高效的数据分析与探索。为此,我们提出了 DTBIA(Digital Twin Brain Immersive Analytics),一个面向类脑研究的沉浸式可视分析系统。DTBIA支持用户在虚拟现实环境中进行从脑区到体素再到切片的多层次探索,通过结合真实比例(Real-Scale)和放大比例(Large-Scale)的大脑模型,分别引入两种交互方式:步行式导航(egocentric walking) 让用户能够在真实比例的大脑模型中直观感知功能数据,飞行式导航(egocentric flying) 则允许用户在放大比例的大脑模型中深入探索复杂的脑连接模式。此外,DTBIA结合 3D边缘聚类算法显著减少视觉干扰,突出关键连接路径,从而支持用户更高效地分析脑网络的时空动态和结构特征。在与神经科学和类脑专家的深度合作中,DTBIA系统通过两个实际案例研究验证了其在揭示脑功能动态模式和拓扑特征上的有效性,为数字孪生脑的研究提供了强有力的工具支持,同时也为神经科学与人工智能的交叉研究开辟了新路径。
该论文被IEEE Pacific Visualization Symposium (PacificVis 2025, TVCG Journal Track)接收。